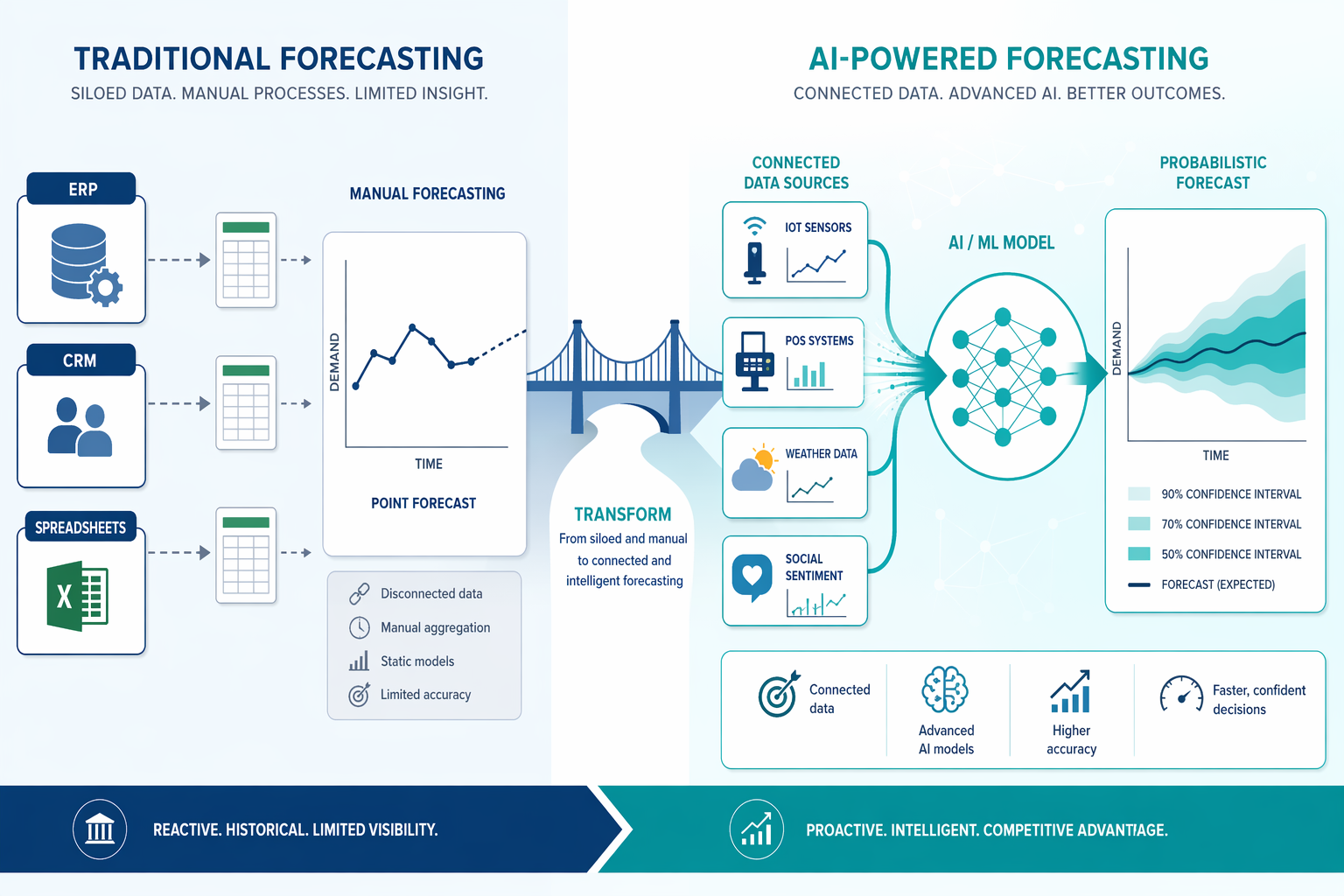
Why AI Forecasting Projects Fail — and It’s Not the Algorithm
Walk into any supply chain conference or browse the vendor marketing materials, and you will hear a consistent story: AI forecasting is a breakthrough, error rates drop by 20% to 50%, and the technology is ready for prime time. The data from McKinsey supports that claim — AI-powered forecasting can reduce errors by that margin and cut product unavailability by up to 65%. Yet the reality inside most planning departments tells a different story. Projects stall, models get shelved, and the promised accuracy gains never materialize.
The root cause is almost never a bad algorithm. Modern machine learning libraries are robust, well-documented, and increasingly accessible. The failures happen upstream — in the data, in the feature definitions, in the integration architecture, and in the organizational readiness to accept machine-generated forecasts. PwC's 2026 Digital Trends in Operations Survey of 767 operations and supply chain leaders found that 87% say poor data quality has hampered their ability to achieve value from digital initiatives. That is not a model problem. That is a preparation problem.
The same PwC survey revealed that 59% of consumer markets leaders cite integration complexity as the top reason technology investments fail to deliver expected results. And Gartner's 2025 research among 120 organizations already deploying AI found that only 23% of supply chain organizations have a formal AI strategy. Without a strategy, without clean data, and without a path to integrate the model into existing workflows, even the most sophisticated forecasting engine will produce outputs that no one trusts and no one uses.

Three Pre-Modeling Mistakes That Undermine AI Forecasting Before It Starts
Simon Joiner, Director of Product Management at o9 Solutions, has observed a pattern across dozens of forecasting implementations: the most damaging errors occur before any machine learning model is ever run. In a published expert perspective, Joiner identifies three specific pre-modeling mistakes that consistently sabotage outcomes.
Mistake 1: Ignoring Data Quality
AI models are ruthlessly literal. If your historical sales data contains unexplainable outliers, missing data points, or shifts in how data was captured — for example, a retailer that changed its point-of-sale system mid-year — the model will treat those artifacts as real patterns. Joiner cites the example of unadjusted coronavirus-period retail data leading to nonsensical trend predictions. The model did not fail. The data did. Cleaning and normalizing historical data is not a one-time preprocessing step; it requires domain knowledge to distinguish genuine demand signals from data collection anomalies.
Mistake 2: Thoughtless Feature Engineering
Machine learning models need well-defined features — variables that encode the business context around each sales observation. Raw historical sales alone are rarely sufficient. Joiner emphasizes that features must go beyond simple binary flags. For example, a promotion flag that says "promotion active" is far less useful than a feature that captures promotion sensitivity categories, such as whether a product is highly elastic to discount depth or relatively inelastic. Without thoughtful feature engineering, the model lacks the context it needs to distinguish between a demand lift caused by a promotion and one caused by seasonality or a competitor's stockout.
Mistake 3: Training with Class Imbalances
In most retail and CPG datasets, non-promotional periods vastly outnumber promotional periods. When you train a model on that imbalanced data, it learns to predict non-promotional demand very well and promotional demand very poorly. The model effectively optimizes for the most common scenario and treats promotional lifts as noise. Joiner notes that this class imbalance problem means the model fails to learn promotional lift effects — precisely the kind of short-term demand spike that planners most need to anticipate. Techniques such as oversampling promotional periods, synthetic data generation, or cost-sensitive learning can help, but the first step is recognizing that the imbalance exists.
Six Broader Implementation Risks Every Planning Team Should Address
Beyond the pre-modeling mistakes, a set of organizational and technical risks can derail even a well-prepared forecasting initiative. These risks are not hypothetical — they are documented across multiple industry surveys and analyst reports. The table below summarizes each risk, its source, and a practical mitigation strategy.
| Risk | Source & Data Point | Mitigation Strategy |
|---|---|---|
| Integration complexity | PwC 2026: 59% of consumer markets leaders cite integration complexity as the top reason tech investments underdeliver | Map your existing ERP, WMS, and TMS architecture before selecting a forecasting platform. Prioritize vendors with pre-built connectors to your core systems. |
| Lack of formal AI strategy | Gartner 2025: Only 23% of supply chain organizations have a formal AI strategy | Develop a documented AI roadmap that defines scope, success metrics, governance, and a phased rollout plan before purchasing any software. |
| Data silos and accessibility | Gartner 2025: Data completeness, availability, and accessibility are ongoing challenges | Establish a centralized data lake or warehouse for planning data. Ensure the forecasting tool can access all relevant sources (POS, inventory, promotions, weather, external events). |
| Employee resistance to AI outputs | RELEX 2026: Only 10% trust AI for critical decisions without human review; 54% prefer hybrid human-in-the-loop | Design workflows that keep planners in the loop. Use AI outputs as recommendations, not directives, during the transition period. |
| Unrealistic ROI expectations | Deloitte 2025: Most organizations achieve returns within 2–4 years; only 6% saw ROI in under a year | Set a 2–4 year timeline for full ROI. Track leading indicators (forecast accuracy, planner time saved) alongside financial metrics. |
| Model governance gaps | PwC 2026: Only 37% are comfortable assigning AI agents to execute full end-to-end processes | Implement model monitoring for drift, accuracy degradation, and data quality changes. Assign clear ownership for model performance and retraining cycles. |
The integration complexity risk deserves special attention. PwC's finding that 59% of consumer markets leaders point to integration as the primary failure mode aligns with practitioner reports across industries. AI forecasting tools do not operate in isolation — they need to pull data from ERP systems, pull inventory positions from WMS platforms, and push forecasts back into planning workflows. If the integration layer is brittle or incomplete, the model's outputs will be stale, incomplete, or simply ignored by downstream systems.
The ROI timeline is another common source of friction. Deloitte's 2025 analysis found that while 85% of organizations increased AI investment, only 6% saw ROI in under a year, with most achieving returns within 2 to 4 years. Planning teams that expect immediate payback often abandon projects before the model has had enough data cycles to demonstrate value. For a deeper exploration of how AI investments translate into financial returns across supply chain and procurement, see our analysis of real AI ROI in procurement and supply chain.
An 11-Step Implementation Framework for AI Forecasting
The following framework synthesizes industry best practices into a structured, actionable process. It is informed by published implementation guidance from Oracle and other practitioners, but has been reorganized and adapted to emphasize the readiness and validation phases where most projects fail. The framework is designed to be iterative — validation and monitoring are not one-time gates but ongoing cycles.

Phase 1: Foundation (Steps 1–3)
- Define objectives and success metrics. What specific business problem are you solving? Inventory reduction? Service level improvement? Promotional effectiveness? Define measurable KPIs — forecast accuracy at the SKU-location-week level, bias, inventory turns, or fill rate — and get stakeholder agreement on targets before any data work begins.
- Assess data readiness. Audit your historical data for completeness, consistency, and quality. Identify gaps, outliers, and periods that need adjustment (e.g., pandemic-era data). Document data lineage and capture methods. This step directly addresses the 87% of organizations where poor data quality has blocked value (PwC 2026).
- Clean and prepare data. Normalize data from multiple sources. Handle missing values, correct outliers where domain knowledge supports it, and align date hierarchies across systems. This is where the pre-modeling mistakes around data quality are resolved.
Phase 2: Modeling (Steps 4–7)
- Engineer features. Build the feature set that encodes business context: promotion calendars, price changes, seasonality indicators, weather data, competitor activity, and macroeconomic signals. This step addresses the thoughtless feature engineering mistake — features must be well-defined and domain-informed.
- Select model type. Choose between statistical baselines (ARIMA, exponential smoothing), machine learning models (gradient boosting, random forest), deep learning approaches (LSTM, Transformer), or ensemble methods. The choice depends on data volume, pattern complexity, and explainability requirements. Oracle's framework notes that 15 industry-standard and proprietary statistical models are available in their platform alone.
- Train the model. Split data into training, validation, and test sets. Address class imbalances — oversample promotional periods or use cost-sensitive learning. Train the model and tune hyperparameters using the validation set.
- Validate and backtest. Run the trained model against historical holdout periods. Measure accuracy, bias, and confidence interval calibration. Compare against a naive baseline and your current forecasting method. If performance is inadequate, revisit feature engineering or model selection.
Phase 3: Deployment and Iteration (Steps 8–11)
- Integrate with existing IT systems. Connect the forecasting engine to your ERP, WMS, and planning platforms. Cloud-based systems are recommended to avoid data silos. Ensure the integration supports real-time or near-real-time data feeds so forecasts reflect current conditions.
- Deploy with human-in-the-loop oversight. Launch the model in a shadow mode or as a parallel recommendation system. Planners review AI-generated forecasts alongside their own and provide feedback. This hybrid approach aligns with the 54% of supply chain leaders who prefer it (RELEX 2026).
- Monitor and iterate. Track model performance over time. Set up alerts for accuracy degradation, data drift, or changes in the underlying demand patterns. Retrain the model on a regular cadence — monthly, quarterly, or when a significant data shift is detected.
- Scale. Once the model is validated in one product category or region, expand to additional SKUs, locations, and time horizons. Document lessons learned and update your data readiness and feature engineering processes based on what worked.
Vendor Evaluation Criteria: What to Look for Beyond Marketing Claims
Once your team has a clear understanding of your data readiness and implementation process, the next step is evaluating vendors. The AI forecasting software market is crowded, and every vendor claims superior accuracy. The following criteria will help you cut through the marketing and assess whether a platform is genuinely suited to your operational context.
| Evaluation Criterion | Why It Matters | What to Ask Vendors |
|---|---|---|
| Multiple comparison partners (MCP) support | A single forecast is less useful than a range. MCP allows planners to compare AI-generated forecasts against statistical baselines, consensus inputs, and manual adjustments. | Does your platform automatically generate and compare multiple forecast versions? Can planners override or blend them? |
| Probabilistic forecasting with confidence intervals | Point forecasts hide uncertainty. Probabilistic outputs give planners a range of possible outcomes and the likelihood of each, enabling better safety stock and contingency planning. | Does your model output confidence intervals? Can we set service-level targets and get the corresponding forecast quantiles? |
| Explainability of model outputs | Planners will not trust a black box. The platform must be able to explain why a particular forecast was generated — which features drove the prediction and by how much. | What explainability features do you offer? Can planners see feature importance scores for individual forecasts? |
| Integration capabilities | The forecasting tool must connect to your existing ERP, WMS, and planning systems. Integration complexity is the #1 reason projects fail (PwC 2026). | Which pre-built connectors do you support? What is the integration architecture? How often can data be synced? |
| Deployment model flexibility | Some organizations require on-premise deployment for data sovereignty or latency reasons. Others prefer SaaS for lower upfront cost and faster updates. | Do you offer SaaS, on-premise, and hybrid deployment? What are the trade-offs for each option? |
| Industry vertical track record | A vendor that has successfully deployed in your industry will have pre-built models, relevant feature libraries, and an understanding of your demand patterns. | Can you provide case studies or references from companies in our industry? What vertical-specific features do you offer? |
For a current overview of the major vendors in this space, including their positioning, target customer profiles, and known capability gaps, see our AI demand planning software vendor landscape snapshot for Q2 2026. That directory provides structured profiles that complement the evaluation criteria above.
Change Management and Organizational Readiness
The technical implementation of AI forecasting is only half the battle. The other half is getting the people in your organization to trust and act on the outputs. The data from RELEX's 2026 State of the Supply Chain report — based on a survey of 500+ supply chain leaders across retail, wholesale, and manufacturing — is sobering: only 10% of supply chain leaders trust AI for making critical decisions without human review. Meanwhile, 54% prefer a hybrid human-in-the-loop approach. That means the vast majority of your planning team will want to keep their hands on the wheel, at least initially.
Building trust in AI-generated forecasts requires a deliberate change management strategy. Here are the key elements, informed by Gartner's five-part plan for touchless forecasting and practitioner experience:
- Define a touchless forecasting vision. Gartner recommends starting with a clear vision of what "touchless" means for your organization — is it fully automated forecasting for stable products, or a phased reduction in manual adjustments over time? Communicate this vision to the planning team so they understand the direction of travel.
- Establish business change parameters. Define which products, categories, or regions will be the first to adopt AI-driven forecasts. Set clear rules for when a planner can override the AI output and when the AI output should be accepted without modification.
- Invest in data literacy and AI training. Planners need to understand how the model works, what its limitations are, and how to interpret probabilistic outputs. Without this understanding, resistance will persist regardless of model accuracy.
- Design human-in-the-loop workflows. The 54% of leaders who prefer a hybrid approach are not being conservative — they are being realistic. Design workflows where the AI generates a forecast, the planner reviews it, and the system captures the planner's adjustments as feedback for model improvement.
- Track adoption metrics alongside accuracy metrics. Monitor not just whether the model is accurate, but whether planners are using it. Track override rates, time spent on manual adjustments, and planner confidence scores over time.
For CPG and retail organizations that have successfully navigated this organizational transition, our structured use case reference for AI demand forecasting in CPG and retail provides concrete examples of how companies have moved from spreadsheet-based planning to AI-assisted forecasting, including the organizational changes that enabled the shift.
Build vs. Buy vs. Hybrid: A Decision Framework for AI Forecasting
One of the most consequential decisions a planning team will make is whether to build a forecasting model in-house, buy a commercial platform, or pursue a hybrid approach that combines both. Each option has distinct trade-offs in terms of cost, speed, control, and ongoing maintenance. The decision matrix below compares the three approaches across the factors that matter most to supply chain organizations.

| Decision Factor | Build | Buy | Hybrid |
|---|---|---|---|
| Internal data science capability | Requires a strong in-house team of ML engineers and data scientists | Minimal — vendor handles model development and maintenance | Moderate — internal team configures and extends a vendor platform |
| Timeline to production | 12–24 months for a production-grade model | 3–6 months with a commercial platform | 6–12 months, depending on customization scope |
| Upfront investment | High — salaries, infrastructure, data pipeline development | Moderate — subscription fees, implementation services | Moderate to high — subscription plus internal development costs |
| Customization and control | Full control over model architecture, features, and data | Limited to vendor's feature set and configuration options | Good balance — customize the parts that matter most |
| Ongoing maintenance burden | High — model retraining, monitoring, infrastructure management | Low — vendor handles updates, monitoring, and support | Moderate — shared responsibility between internal team and vendor |
| Integration complexity | Full control over integration architecture, but requires building connectors | Pre-built connectors to major ERP/WMS/TMS platforms | Mix of pre-built and custom integrations |
| Best suited for | Organizations with unique demand patterns, strong data science teams, and long investment horizons | Organizations that need fast deployment, have limited ML expertise, and want predictable costs | Most organizations — combines speed of buy with flexibility of build |
For most supply chain organizations, the hybrid approach offers the best balance of speed, control, and risk. A commercial platform provides the forecasting engine, pre-built integrations, and ongoing model maintenance, while an internal team configures the feature set, manages data pipelines, and retains ownership of the planning process. This approach also aligns with the organizational reality that only 37% of leaders are comfortable assigning AI agents to execute full end-to-end processes (PwC 2026) — a hybrid model keeps humans in the loop while still capturing the benefits of AI-driven accuracy.
The build approach is rarely justified unless your organization has a genuinely unique demand pattern that no commercial platform handles well, or you have a mature data science team with experience in time-series forecasting. The buy approach works well for organizations that need to move quickly and have relatively standard demand patterns, but it carries the risk of vendor lock-in and limited customization. The hybrid approach, while requiring more coordination, gives you the flexibility to adapt as your forecasting maturity grows.
For a deeper look at how demand planning software is transforming forecast accuracy and inventory costs across industries, see our business case analysis of the transition from spreadsheets to AI-driven planning.
Comments
Join the discussion with an anonymous comment.