For decades, demand forecasting in supply chain meant one thing: feeding historical sales data into a statistical model — exponential smoothing, ARIMA, or a simple moving average — and projecting that pattern forward. The assumption was that the future would, in its essential shape, resemble the past. That assumption is breaking down. Product lifecycles are shorter, promotion calendars are denser, and external shocks — tariff shifts, port disruptions, sudden demand spikes — arrive faster than any quarterly model refresh can accommodate.
AI-based forecasting methods have emerged as an alternative, but the conversation around them is often polarized. Vendors claim AI is universally superior; skeptics point to black-box opacity and data requirements that most mid-market organizations cannot meet. The reality is more nuanced. This primer walks through how each approach works, where each excels, and — most importantly — how to decide when to use which, drawing on frameworks from Bain & Company, McKinsey, and Gartner.
How Traditional Statistical Forecasting Works
Traditional forecasting methods are built on time-series analysis. They assume that historical patterns — trend, seasonality, and cyclicality — will persist into the future, and they use mathematical formulas to extrapolate those patterns. The three most common families are:
- Time-series decomposition: Breaks historical data into trend, seasonal, and residual components, then projects each forward independently. Works well when seasonality is stable and the trend is linear.
- Exponential smoothing (e.g., Holt-Winters): Assigns exponentially decreasing weights to older observations. Simple, computationally cheap, and interpretable — the default method in most ERP forecasting modules.
- Regression-based models: Incorporate one or more independent variables (price, promotion spend, GDP growth) alongside time. More flexible than pure time-series but still assume a fixed functional relationship between inputs and demand.
The strengths of these methods are real and often underappreciated. They require relatively little data — a few seasons' worth of history can produce a usable forecast. They are transparent: a planner can open the model, see the formula, and understand exactly why a number was produced. And they are computationally lightweight, making them practical for organizations running forecasts on ERP systems that were never designed for high-performance computing.
But the limitations are equally structural. Statistical models cannot detect non-linear relationships. They cannot incorporate external signals — weather data, social sentiment, competitor pricing — unless those signals are explicitly coded as regression variables, which requires manual specification and constant maintenance. Most critically, they assume stationarity: that the underlying data-generating process does not change. When a pandemic, a trade war, or a sudden shift in consumer behavior breaks that assumption, the forecast breaks with it.
How AI/ML Forecasting Methods Work
AI-based forecasting replaces fixed mathematical formulas with algorithms that learn patterns directly from data. Rather than assuming a linear trend or a fixed seasonal pattern, these models discover relationships — including non-linear and interacting effects — that a human analyst might never think to specify.
The most common techniques in production supply chain forecasting include:
- Gradient boosting machines (XGBoost, LightGBM, CatBoost): Ensemble methods that combine hundreds of weak decision trees. They handle mixed data types (numeric, categorical, missing values) well and are often the top-performing method in structured-data forecasting competitions.
- Neural networks (including LSTM and Transformer architectures): Designed to capture sequential dependencies and long-range patterns. Particularly effective when demand signals are noisy and the relationship between inputs and outputs is highly non-linear.
- Supervised learning with feature engineering: The model is trained on historical data where the target (actual demand) is known, and features include not just lagged sales but also external variables — promotion calendars, weather forecasts, economic indicators, web search trends.
A key distinction from traditional methods is that AI models are typically trained on groups of SKUs simultaneously, learning cross-series patterns. Bain & Company notes that machine learning models can model complicated relationships across thousands of series at once, but they work as black boxes and are computationally slow when applied to individual series in isolation.
Side-by-Side Comparison: Traditional vs. AI Forecasting
The table below summarizes the key differences across the dimensions that matter most to supply chain planners evaluating a method change.
| Dimension | Traditional Statistical | AI / Machine Learning |
|---|---|---|
| Primary data sources | Historical sales only (internal) | Historical sales + external signals (weather, promotions, economic data, social sentiment) |
| Responsiveness to change | Slow — requires manual model re-specification when patterns shift | Fast — models can retrain automatically as new data arrives |
| Pattern recognition | Linear trends, fixed seasonality | Non-linear, interacting, and conditional patterns |
| Forecast output type | Point forecast (single number) | Probabilistic forecast (distribution with confidence intervals) |
| Manual effort required | High — data prep, model selection, parameter tuning, exception handling | Low to moderate after initial setup — models self-optimize but require monitoring |
| Data volume needed | Low — works with 2–3 years of history | Higher — benefits from 3+ years and multiple external features |
| Interpretability | High — formula is transparent | Low to medium — requires explainability tools (SHAP, LIME) for black-box models |
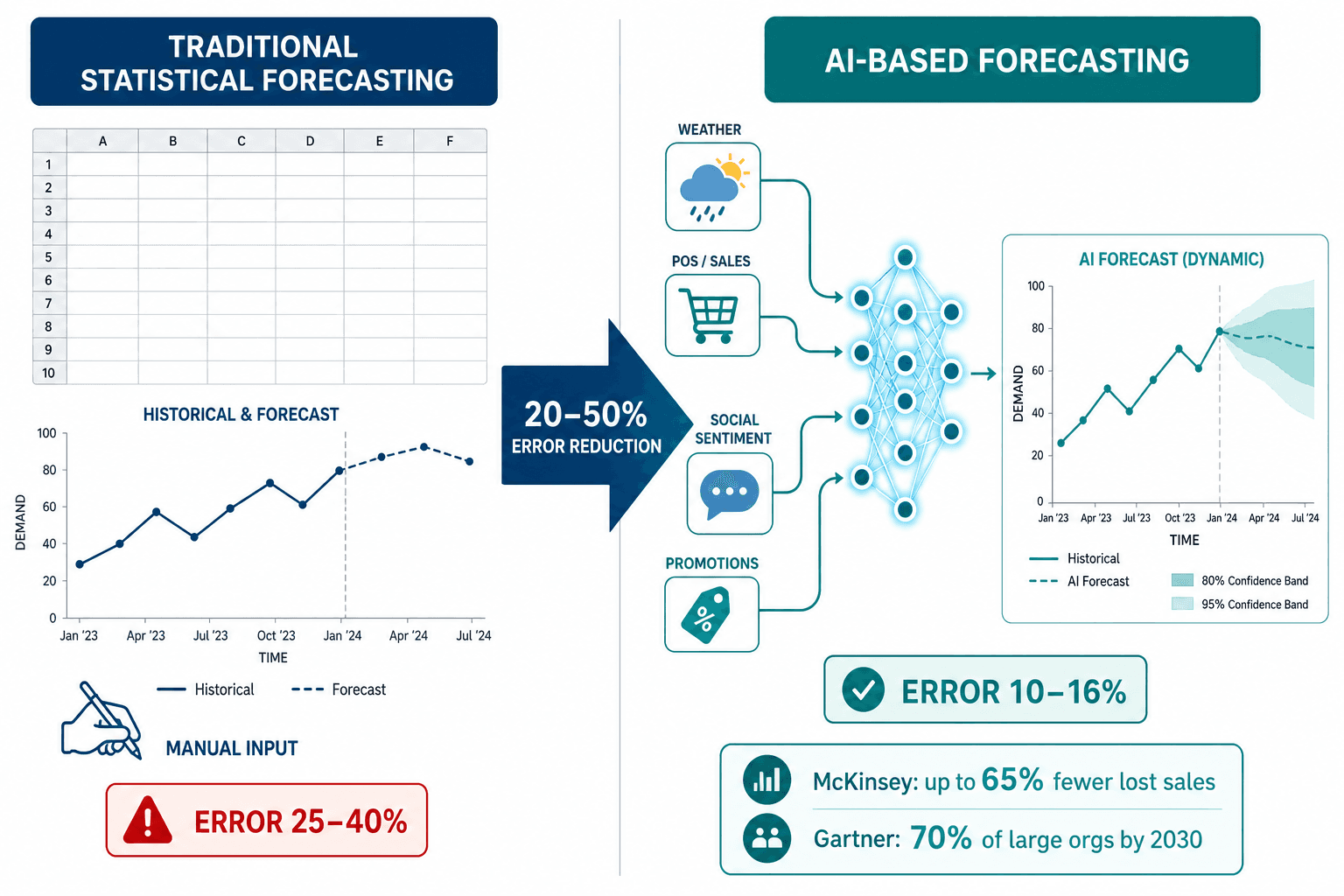
The performance gap is not theoretical. McKinsey's analysis found that applying AI-driven forecasting to supply chain management can reduce forecast errors by 20 to 50 percent, translating into a reduction in lost sales and product unavailability of up to 65 percent, warehousing cost reductions of 5 to 10 percent, and administration cost reductions of 25 to 40 percent. These figures come from a 2022 study and remain the most widely cited industry benchmark.
When Each Approach Works Best
The decision between traditional and AI methods depends on three factors: demand volatility, SKU complexity, and the availability of external demand drivers.
Statistical methods perform well when demand is stable, seasonality is predictable, and the number of SKUs is manageable. A commodity chemical with a 5-year history of flat demand and no promotional activity does not need a neural network. Exponential smoothing will produce a forecast that is nearly as accurate, fully interpretable, and trivial to maintain.
AI methods add value when any of those conditions is absent. High SKU complexity — thousands of items with different demand patterns — is where ML's ability to learn cross-series relationships pays off. Volatile demand driven by promotions, weather, or macroeconomic shifts is where AI's capacity to incorporate external signals and detect non-linear patterns becomes decisive. The food and beverage sector, for example, has a median forecast error of approximately 25%, and durable consumer products can see error rates up to 50% — precisely the environments where AI's 20–50% error reduction is most impactful.
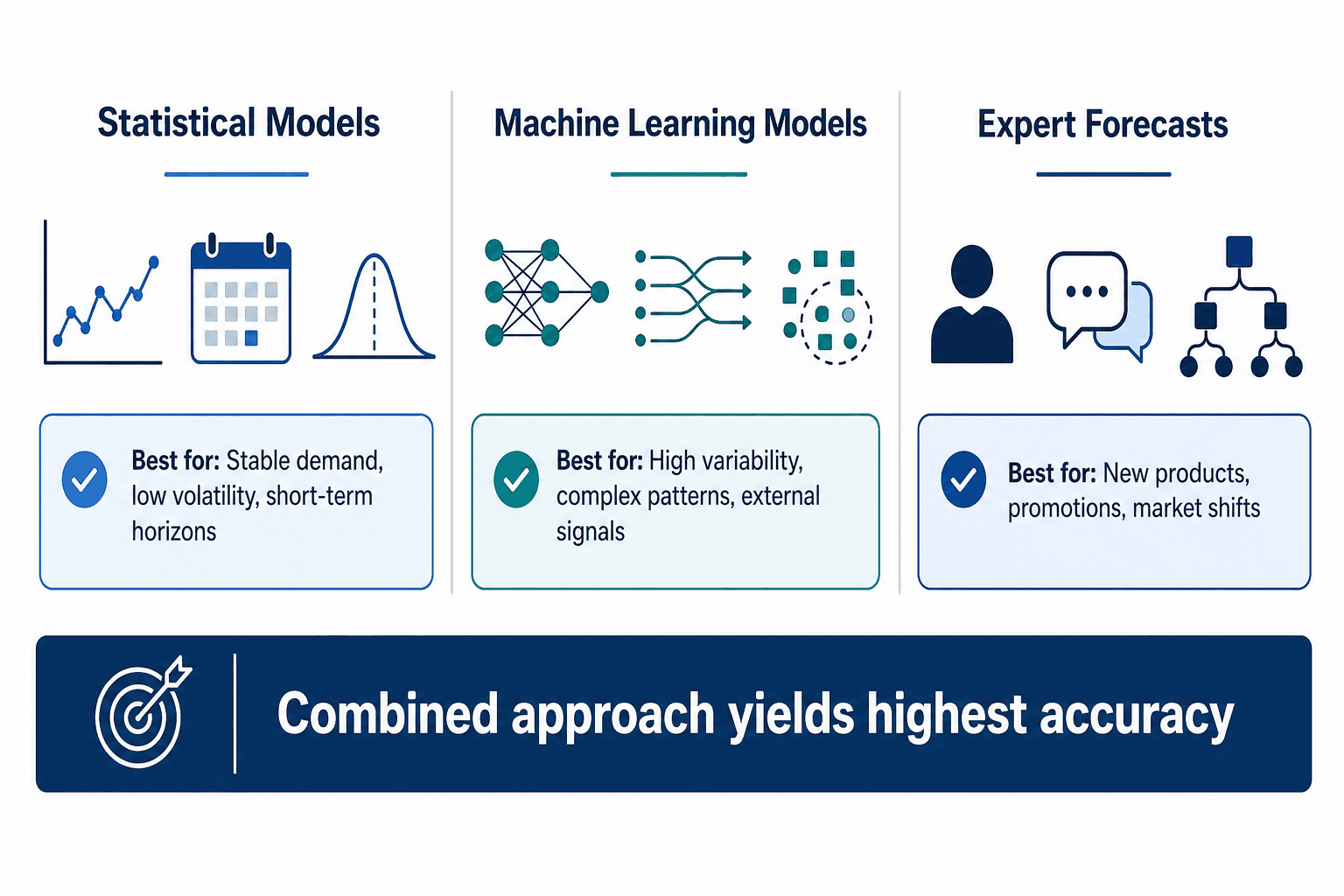
Bain's Three-Model Framework
Bain & Company provides a structured way to think about the choice. Their framework categorizes forecasting approaches into three types, each with distinct strengths:
| Model Type | Best For | Key Limitation |
|---|---|---|
| Statistical models | Individual series with stable patterns (e.g., a single SKU in a store) | Cannot model complex, non-linear relationships across many series |
| Machine learning models | Large groups of series with complex, interacting demand drivers | Black-box outputs; computationally slow for individual series |
| Expert forecasts | New products, promotions, or scenarios with no historical precedent | Prone to cognitive bias; inconsistent across individuals |
Bain's key insight is that the methods are complementary, not mutually exclusive. A large grocery chain improved forecast accuracy by combining statistical and ML models. A food company that combined automated forecasts with expert qualitative input achieved millions in inventory cost savings and higher revenue. The choice should be driven by user needs: if planners need interpretability to make decisions, statistical or expert-combined methods may be preferred over black-box ML.
McKinsey's Four Data-Light Strategies for AI Forecasting
A common objection to AI forecasting is that it requires massive datasets — years of clean historical data across thousands of SKUs. McKinsey's research directly addresses this concern, identifying four strategies that make AI forecasting viable even when historical data is limited:
- Choose the right model complexity: When sample sizes are small, simpler models (e.g., regularized linear regression or shallow decision trees) outperform complex neural networks. Complexity should scale with data availability, not ambition.
- Leverage data smoothing and augmentation: Techniques like time-series aggregation (forecasting at a higher level and disaggregating), synthetic data generation, and transfer learning from related product categories can stretch limited data further.
- Prepare for prediction uncertainty with scenario tools: Rather than relying on a single point forecast, use what-if scenario modeling to understand the range of possible outcomes. This is especially important when historical data does not cover the range of future conditions.
- Incorporate external data APIs: Even with limited internal history, external data sources — weather forecasts, economic indicators, social media trends — can provide signals that compensate for short internal time series.
McKinsey's call-center case study illustrates the approach: by applying these data-light strategies, the organization improved forecast accuracy by almost 10% for call volume, with cost reductions of about 10 to 15% and service level improvements of 5 to 10%.
The Transition Path: From Excel/ERP to Hybrid to Full AI Forecasting
Organizations rarely jump from spreadsheet-based forecasting to fully automated AI in a single project. The transition typically follows a staged maturity model, with clear decision points at each stage.
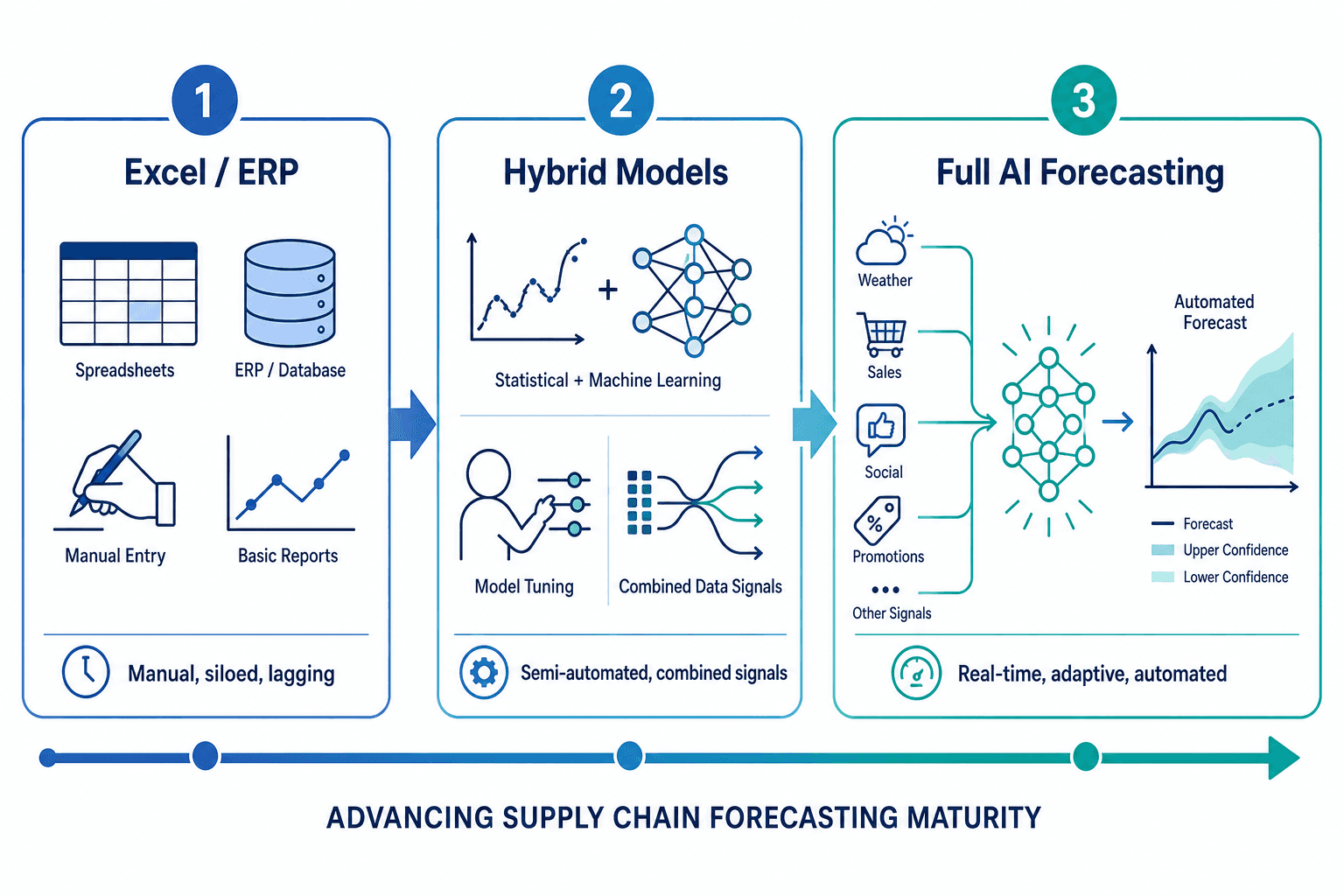
| Stage | Characteristics | When to Advance |
|---|---|---|
| Stage 1: Manual / ERP-based | Spreadsheets or ERP modules with statistical methods; forecasts updated monthly or weekly; high manual effort for exception handling | When forecast error consistently exceeds 30% for stable SKUs, or when planner time is consumed by data wrangling rather than analysis |
| Stage 2: Hybrid models | Statistical baseline + ML overlay for high-volatility SKUs; automated data feeds from ERP and external sources; probabilistic outputs for key items | When hybrid models demonstrate 15–20% lower error than statistical alone on a pilot set of 50–100 SKUs over 3–6 months |
| Stage 3: Full AI forecasting | ML models trained on all SKUs with automated retraining; real-time external signal integration; touchless forecasting for routine items with human review only for exceptions | When organizational trust in model outputs is established, governance processes are in place, and the data infrastructure supports real-time updates |
Gartner's five-part adoption plan provides a complementary roadmap: (1) define a touchless forecasting vision, (2) establish business change parameters, (3) define a touchless data strategy that moves beyond sole reliance on historical sales data, (4) create a technology enablement roadmap, and (5) plan for the adoption journey with trust-building measures.
The urgency of this transition is underscored by Gartner's prediction that 70% of large-scale organizations will adopt AI-based forecasting to predict future demand by 2030. Organizations that delay risk falling behind on both capability and talent — the planners who understand hybrid forecasting will be in significantly higher demand than those who only know ERP-based methods.
Common Mistakes and How to Avoid Them
The most common error in forecasting method selection is assuming that AI is always superior. It is not. For stable, low-SKU-count environments, a well-tuned exponential smoothing model will match or beat a neural network at a fraction of the implementation cost. The Bain framework exists precisely to prevent this mistake: match the method to the problem, not to the hype.
- Ignoring model governance and explainability: Black-box ML models can produce excellent forecasts, but if planners cannot understand why a forecast was generated, they will override it — defeating the purpose. Invest in explainability tools (SHAP, LIME) and maintain a human-in-the-loop for exception handling.
- Over-relying on black-box outputs without validation: Every forecast — regardless of method — should be back-tested against actuals. A model that performs well on training data may fail in production due to data drift, changing market conditions, or integration errors.
- Underestimating data quality requirements: AI models are more sensitive to data quality than statistical methods. Missing values, inconsistent taxonomies, and lagged data feeds will degrade performance faster than a flawed algorithm choice.
- Skipping the hybrid stage: Organizations that attempt to go directly from manual forecasting to full AI often fail because they lack the data infrastructure, organizational trust, and governance processes that the hybrid stage builds.
Gartner's research adds a sobering data point: more than 70% of recently implemented ERP initiatives will fail to fully meet their original business case goals by 2027, with as many as 25% failing catastrophically. The same failure modes — poor data readiness, inadequate change management, unrealistic expectations — apply to AI forecasting implementations. Treating the technology as a plug-and-play replacement for existing processes rather than as a capability that requires organizational transformation is the fastest path to a failed project.
The choice between traditional and AI forecasting is not a binary technology decision. It is a strategic decision about where to invest analytical resources based on the specific demand characteristics of each product category. Statistical methods will remain the right choice for stable, low-complexity environments. AI methods will increasingly dominate high-variability, high-SKU-count environments. The organizations that will lead in forecasting capability are those that learn to deploy both — and know when to use which.