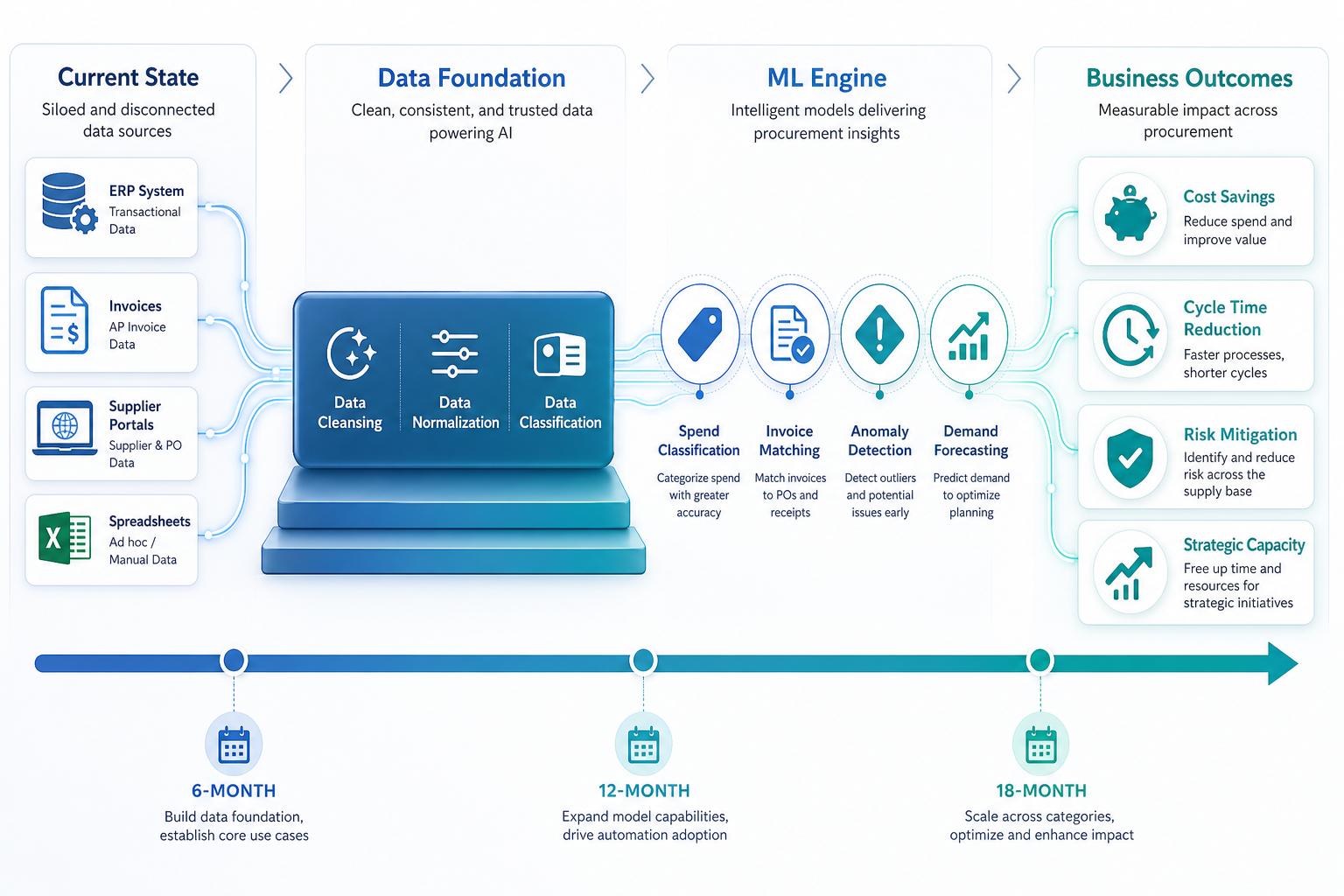
Why ML in Procurement Is Different from Prior Automation Waves
Procurement teams have automated before. Robotic process automation (RPA) handled repetitive keystrokes. Rule-based systems flagged purchase orders that exceeded thresholds. These tools followed explicit instructions: if X, then Y. Machine learning does not work that way. It learns patterns from data, makes probabilistic predictions, and improves as it processes more transactions. That shift — from deterministic rules to probabilistic models — changes how you plan, govern, and scale the technology.
The gap between experimentation and production is stark. According to the Hackett Group's 2025 procurement study, 49% of procurement teams have run an AI pilot, but only 4% have achieved large-scale deployment. That 45-point gap is not a technology problem. It is an execution problem. Teams pilot in a silo, fail to connect the model to clean data, skip governance design, and cannot articulate a business case that survives a CFO review.
The urgency to close this gap is rising. McKinsey reports that procurement teams now manage 50% more spend per FTE than five years ago, while headcount has not kept pace. The Hackett Group found that procurement workloads grew 10% in the past year while budgets grew just 1%, creating a 9% efficiency gap. ML is not a nice-to-have experiment; it is the primary lever to absorb that imbalance.
This roadmap converts that 4% success rate into a repeatable sequence. It assumes you have already diagnosed your readiness gaps — if you have not, start with ChainSignal's AI Readiness Gap in Procurement assessment before proceeding. The six phases below cover data preparation, use-case selection, governance model design, scaling mechanics, and measurement — in that order.
Phase 1: Assess Readiness and Define Outcomes
Before you evaluate a single vendor or write a line of code, you need a clear picture of where you stand. The most common failure mode in procurement ML is starting with the technology and working backward to find a problem. That approach produces pilots that solve nothing and die after six months.
A proper assessment covers three dimensions:
- Data quality and completeness. Gartner reports that 74% of procurement leaders say their data is not AI-ready. You need to know your field-completeness percentage, the number of supplier-name variants in your ERP, and the percentage of spend that sits outside your core system (tail spend). If you cannot answer these questions, you are not ready to select a use case.
- Process pain points. Which procurement processes consume the most FTE hours? Where are cycle times longest? Where do errors create downstream rework? Prioritize processes that are high-volume, repetitive, and data-intensive — these are the natural candidates for ML.
- Measurable business outcomes. Define what success looks like in concrete terms: reduce invoice processing time by 40%, increase spend-under-management by 15%, cut tail-spend leakage by 10%. Without these targets, you cannot calculate ROI or know when to stop iterating.
The assessment phase should produce a readiness scorecard and a shortlist of 2-3 use cases that align with your data maturity. If your scorecard reveals major gaps — less than 60% field completeness, no supplier master data management, or no centralized spend cube — address those before moving to Phase 2. ChainSignal's AI Readiness Gap in Procurement provides a structured diagnostic for this step.
Phase 2: Build the Data Foundation
Machine learning models are only as good as the data they train on. Procurement data is notoriously messy: supplier names appear in 15 or more different formats across systems, category codes are inconsistently applied, and tail spend transactions often lack any classification at all. Building a usable data foundation requires three specific investments.
| Data Requirement | Minimum Threshold | Why It Matters |
|---|---|---|
| Historical spend data | 2+ years; 3-5 years preferred | ML models need enough transaction history to learn seasonal patterns, supplier behavior, and category trends. Less than 2 years produces unreliable predictions. |
| Field completeness | 80%+ of core fields populated | Missing supplier IDs, category codes, or amounts create gaps that models cannot fill. The 80% threshold is the minimum for supervised learning to produce stable classifications. |
| Supplier name normalization | Single canonical name per supplier | ML fuzzy matching can resolve 15+ name variants, but the model needs a training set where the canonical mapping is already established. Without it, the model learns the noise. |
| Tail spend visibility | At least 60% of total spend captured | Tail spend — the long tail of low-value, infrequent transactions — is where most classification errors occur. ML can improve tail spend visibility over time, but the initial training set must be representative. |
The good news: you do not need a perfect data lake before you start. The APQC finding that 8 out of 10 organizations see data quality improve through AI implementation is not a marketing claim — it reflects the reality that preparing data for ML forces discipline. Supplier master data gets cleaned. Missing fields get populated. Duplicate records get merged. The data foundation improves as a byproduct of the implementation process.
Tail spend is the hardest data challenge. Most procurement systems capture 70-80% of spend in structured, classified form. The remaining 20-30% — small purchases, one-off suppliers, non-PO invoices — lives in unstructured or semi-structured formats. ML-based spend analysis tools are specifically designed to address this gap. ChainSignal's AI Spend Analysis Automation guide covers how to approach tail spend visibility with ML.
Phase 3: Start with High-Impact, Low-Complexity Use Cases
The most common mistake in procurement ML is starting with the most ambitious use case — predictive supplier risk scoring, autonomous negotiation, or demand forecasting — before the data foundation and organizational trust exist. These use cases require mature data pipelines, cross-functional buy-in, and governance models that take months to establish. Start with use cases that deliver measurable value within 6-12 months and build organizational confidence.
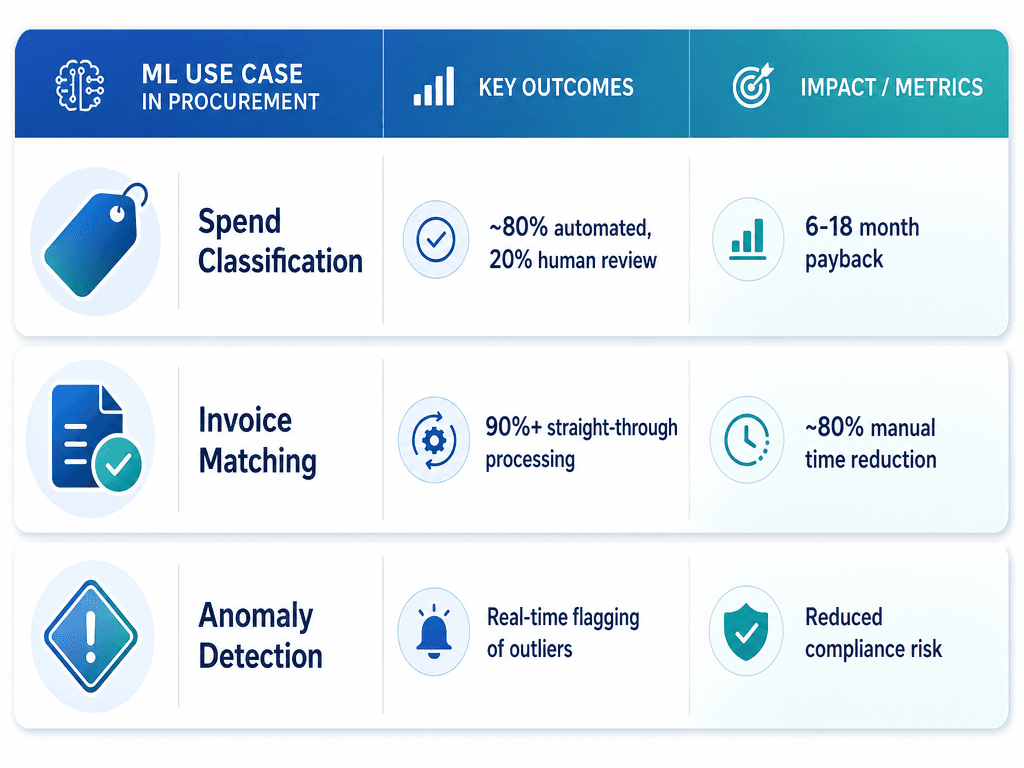
Three use cases meet the high-impact, low-complexity criteria for most procurement organizations:
| Use Case | What It Does | Automation Rate | Reported Outcomes | Typical Payback |
|---|---|---|---|---|
| Spend Classification | Automatically assigns category codes (UNSPSC, custom taxonomies) to purchase orders and invoices using supervised ML. | ~80% automated; ~20% requires human review (Sievo) | Reduces manual classification effort by 70-80%; improves spend visibility for tail-spend categories. | 6-18 months (Precoro) |
| Invoice Matching | Matches invoice line items to purchase orders and receiving documents using ML-based fuzzy matching and anomaly detection. | 90%+ straight-through processing (Precoro) | Reduces manual invoice processing time by ~80%; cuts cycle time from days to hours. | 6-12 months |
| Anomaly Detection | Flags invoices, purchase orders, or supplier payments that deviate from historical patterns — duplicate payments, pricing errors, unusual quantities. | Catches 90-97% of problematic invoices (Precoro) | Reduces compliance risk and payment leakage; frees AP teams from manual review of every transaction. | 6-12 months |
Spend classification is the most common entry point. According to Deloitte's 2025 CPO survey, spend analytics and dashboarding is the top GenAI priority for 53.44% of procurement leaders. While that survey covers generative AI specifically, the underlying need — better visibility into what the organization is buying — is the same driver for ML-based classification. A global SaaS company, cited in Supply Chain Management Review, used AI-based supplier analysis to cut software expenses by 23% and halve sourcing cycle times.
Invoice matching is the second most accessible use case because the data is already structured: purchase orders, invoices, and receiving documents exist in your ERP. The ML model learns the matching rules from historical data and handles exceptions — partial matches, quantity discrepancies, price variances — that rule-based systems cannot resolve. Precoro reports that organizations achieve 95%+ straight-through processing rates after the model has been trained on 6-12 months of historical data.
Anomaly detection is the third recommended starting use case because it directly addresses a pain point every procurement team shares: how to catch errors without reviewing every transaction. ML-based anomaly detection models learn the normal range of invoice amounts, payment terms, and supplier behavior, then flag deviations in real time. Precoro reports that these models catch 90-97% of problematic invoices, compared to the 40-60% detection rate of rule-based systems.
For detailed real-world examples of these use cases in action, see ChainSignal's AI in Procurement: 10 Real-World Examples with Measurable Outcomes.
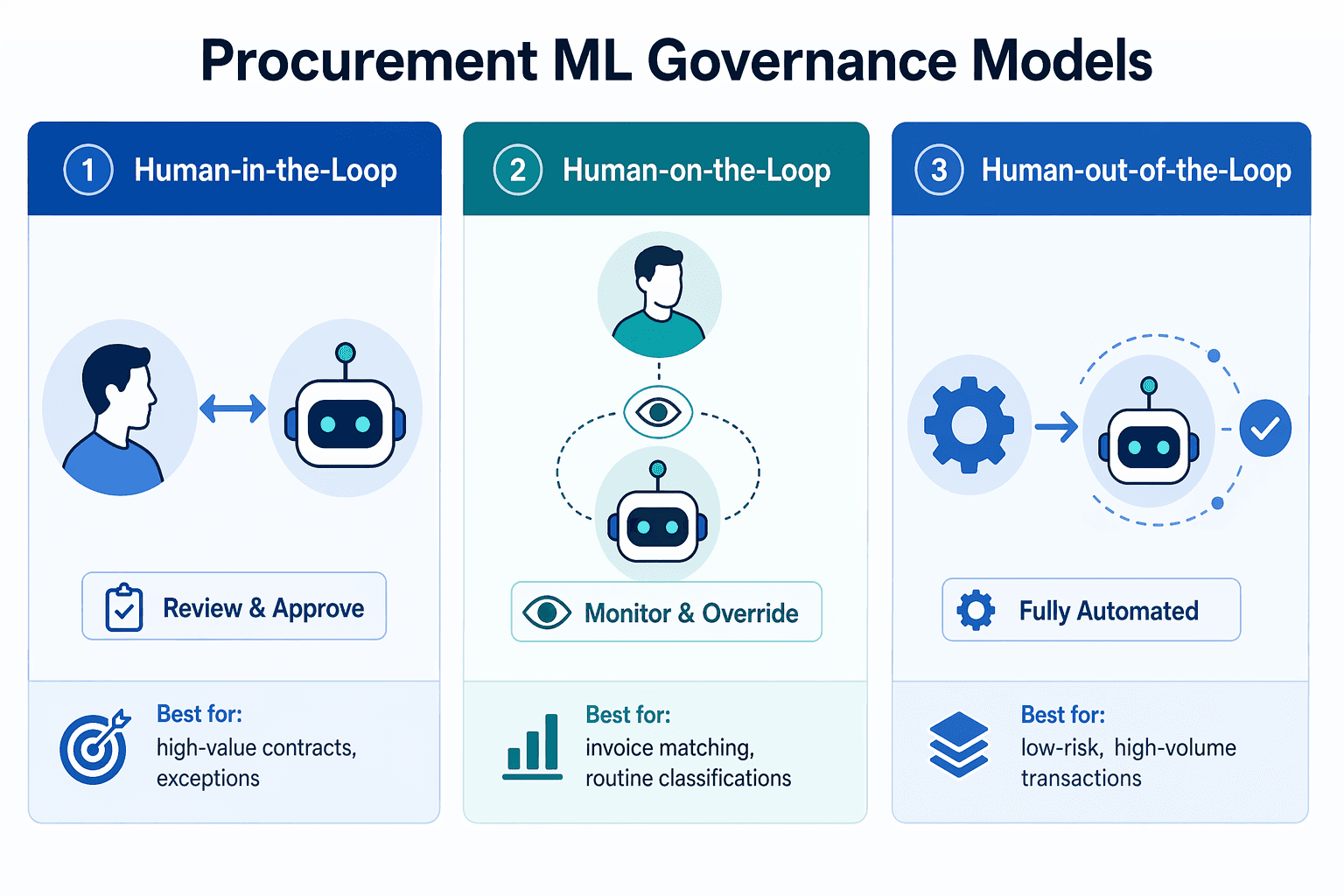
Phase 4: Choose the Right Governance Model
Governance is not an afterthought — it is the mechanism that determines whether your ML deployment builds trust or erodes it. Procurement ML models make predictions that affect real spending decisions. A misclassified supplier category may not matter much. An incorrectly approved invoice for $500,000 does. The governance model you choose defines how much autonomy the system has and where human judgment intervenes.
Three governance models are relevant for procurement ML, each suited to different use cases and risk levels:
| Model | How It Works | Best For | Risk Level |
|---|---|---|---|
| Human-in-the-Loop (HITL) | Every ML output is reviewed by a human before it becomes an action. The model makes a recommendation; the human approves or rejects it. | High-value contracts, supplier onboarding, exceptions to policy, first-time classifications. | Low — human maintains full control. Suitable for initial deployment and high-risk decisions. |
| Human-on-the-Loop (HOTL) | ML operates autonomously for routine transactions. Humans monitor aggregated outputs and intervene only when the model flags an exception or confidence drops below a threshold. | Invoice matching for standard POs, routine spend classification, anomaly detection alerts. | Medium — model handles most transactions autonomously; human oversight is periodic and exception-based. |
| Human-out-of-the-Loop (HOOTL) | ML operates fully autonomously. No human review for individual transactions. Governance is limited to periodic audits and model performance monitoring. | Low-value, high-volume transactions where error cost is minimal. Rare in procurement today. | High — requires mature model validation, drift monitoring, and audit trails. Not recommended for initial deployment. |
For most procurement organizations starting their ML journey, the recommended approach is HITL for the first 6-12 months, then gradually transition to HOTL as the model's accuracy and the team's confidence grow. HOOTL is rarely appropriate for procurement use cases today, given the financial and compliance risks involved.
The governance model also determines your audit trail requirements. Under HITL, every decision has a human signature — the audit trail is straightforward. Under HOTL, you need to log every model output, every human override, and every threshold that triggered an exception. Under HOOTL, you need continuous model performance monitoring, drift detection, and periodic validation against a holdout dataset.
Phase 5: Scale from Pilot to Enterprise-Wide Deployment
Scaling is where most procurement ML initiatives fail. The Hackett Group's finding that only 4% of teams achieve large-scale deployment is not because the technology does not work — it is because the organizational infrastructure for scaling was never built. Scaling requires four deliberate investments.
- Expand from one category to multiple. Start with a single high-volume category (IT hardware, MRO, or professional services). Prove the model works, document the implementation playbook, then expand to adjacent categories. Each category may require retraining the model on different data patterns, but the infrastructure — data pipeline, governance model, integration with ERP — transfers directly.
- Add predictive use cases. Once the foundational use cases (classification, matching, anomaly detection) are stable, introduce predictive models: supplier risk scoring, demand forecasting for direct materials, and price prediction for commodities. These use cases require more data and more sophisticated models, but they also deliver higher ROI. McKinsey's Pareto principle applies here: a handful of high-value use cases delivers 60-80% of total value.
- Build a dedicated analytics team. McKinsey found that best-in-class companies place 22% of their procurement employees in analytics teams. This is not a side project for the existing procurement team — it requires dedicated data engineers, data scientists, and domain experts who understand both ML and procurement processes. The correlation between analytical resources and AI maturity is direct.
- Establish a transformation office. Scaling ML across an enterprise requires coordination across procurement, IT, finance, and legal. A transformation office tracks impact weekly, resolves cross-functional blockers, and maintains the implementation roadmap. McKinsey recommends weekly impact tracking for the first 12 months of scaling.
The single biggest barrier to scaling is organizational, not technical. Deloitte's 2025 procurement survey found that siloed working is the top barrier to value delivery, cited by 57% of respondents. Competing priorities was the second most common barrier at 46%. If your procurement ML initiative is owned solely by the procurement team without IT partnership, executive sponsorship, and cross-functional governance, it will stall at the pilot stage.
For a detailed analysis of the patterns that separate successful scaling from stalled pilots, see ChainSignal's From Pilot to Production: How Procurement Teams Are Actually Deploying AI.
Phase 6: Measure Success and Avoid Common Pitfalls
Measurement is not a retrospective activity — it is the mechanism that keeps your implementation on track. Define your KPIs before you deploy the first model, and track them weekly during the first 12 months. The right KPIs vary by use case, but four metrics apply across most procurement ML deployments.
| KPI | What It Measures | Target Benchmark | How to Track |
|---|---|---|---|
| Time savings per FTE | Hours saved per week per procurement team member through automation of manual tasks. | 40-80% reduction in manual processing time for targeted tasks (Precoro). | Time-tracking surveys before and after deployment; system logs of automated vs. manual transactions. |
| Cost reduction | Direct savings from better spend visibility, reduced maverick spend, and improved negotiation leverage. | 10-20% reduction in category spend for targeted categories (McKinsey). | Compare category spend before and after ML deployment, controlling for market price changes. |
| Cycle time improvement | Reduction in time from requisition to purchase order, or from invoice receipt to payment. | 40-60% reduction in sourcing cycle time (SCMR case example). | ERP timestamps for each process step; compare pre- and post-deployment averages. |
| Forecast accuracy | Accuracy of ML-based demand or price predictions compared to actual outcomes. | Varies by category; 15-25% improvement over baseline forecasting methods. | Compare predicted vs. actual values; track mean absolute percentage error (MAPE) monthly. |
Tie ROI directly to implementation steps. After Phase 3 (spend classification deployment), expect a 6-18 month payback period based on Precoro's customer-reported data. After Phase 4 (invoice matching), expect 80% reduction in manual processing time. After Phase 5 (scaling to predictive use cases), expect the ROI to compound as multiple models share the same data infrastructure.
Three common pitfalls will undermine your measurement if you do not address them proactively:
- Data quality gaps. If your training data has systematic errors — missing supplier IDs, incorrect category codes, duplicate records — your model will learn those errors. The result: high accuracy on training data, poor performance in production. Mitigate this by validating your training dataset against a manually curated holdout sample before deployment.
- Change resistance. Procurement teams that have spent years building expertise in manual classification or invoice matching may resist automation. The BCG found that 89% of organizations say their workforce needs improved AI skills, but only 6% have started upskilling. Address this by involving procurement team members in the model design process, not just the deployment.
- The pilot trap. Running a successful pilot on a single category or a single supplier does not guarantee successful scaling. The pilot trap occurs when teams celebrate the pilot results but never build the infrastructure — data pipeline, governance model, analytics team — required for enterprise-wide deployment. The 49% pilot vs. 4% scale gap is the pilot trap in action.
For a comprehensive analysis of procurement ML ROI metrics and case studies, see ChainSignal's From Pilot to Profit: The Real ROI of AI in Procurement and Supply Chain.
Comments
Join the discussion with an anonymous comment.