
Why Most HITL Procurement AI Deployments Fail at the Reviewer Layer
When autonomous procurement AI implementations break down in production, the post-mortem rarely points to the model. The model is often performing exactly as designed. What breaks is the human oversight layer — the reviewers, the interface, the thresholds, and the feedback mechanisms that were supposed to keep the system honest.
The canonical failure signal is a review queue showing approval rates above 99% within 48 hours of go-live. That number does not mean the AI is working flawlessly. It means reviewers have stopped reading. A blanket review queue with no structural enforcement of engagement produces rubber-stamping at industrial scale — which is functionally equivalent to no human oversight at all, except that it generates audit logs suggesting otherwise.
Three failure modes account for most of the degradation. First, automation complacency: as system accuracy climbs above 95%, reviewers internalize the base rate and start approving by default. Second, poor reviewer tooling: interfaces that show only the flagged action without context force reviewers to make decisions on incomplete information, which accelerates trust in the AI's judgment. Third, uncalibrated thresholds: routing logic that sends too many low-risk actions to human review creates volume fatigue, while routing logic that relies solely on LLM confidence scores misses errors precisely in the high-confidence band where reviewers are least vigilant.
This guide addresses the operational layer. Pattern selection — which of the five HITL patterns to apply to which procurement decision type — is the starting point, not the destination. The implementation problems that determine whether human oversight actually functions in production are reviewer workflow design, complacency mitigation, confidence routing architecture, trust calibration mechanics, and feedback loop construction. Each of these requires deliberate engineering that most governance frameworks either skip or treat as an afterthought.
The Five HITL Patterns Applied to Autonomous Procurement Decisions
Before addressing implementation mechanics, it is useful to establish the pattern taxonomy that frames the rest of this guide. Five patterns cover the range of procurement decision contexts where human oversight is operationally relevant. Each maps to a different decision characteristic — reversibility, authority level, volume, output type, and risk distribution.
| Pattern | Procurement Decision Context | Key Characteristic | Primary Failure Mode |
|---|---|---|---|
| Approval Gate | Irreversible commitments: contract execution, sole-source awards, large capital purchases | Human must approve before execution; no autonomous action taken | Becomes a bottleneck when threshold is set too low; reviewer fatigue if volume is high |
| Escalation Ladder | Tiered spend authority: routine POs below threshold execute autonomously; escalates by spend band or supplier risk tier | Autonomy expands as spend decreases or risk decreases | Threshold miscalibration routes too much or too little to human review |
| Multi-Signal Confidence Routing | High-volume mixed-risk actions: invoice matching, catalog purchases, supplier onboarding checks | Composite signal determines routing; not binary approve/reject | Overreliance on raw LLM confidence scores misses errors in the high-confidence band |
| Collaborative Drafting | Nuanced outputs requiring human co-creation: RFP language, supplier negotiation positions, contract clause recommendations | AI generates a draft; human refines before any action is taken | Reviewers accept drafts without substantive editing; AI framing biases the final output |
| Audit with Smart Sampling | High-volume, lower-risk routine actions: standard catalog reorders, pre-approved supplier transactions within tolerance | Actions execute autonomously; a targeted sample is reviewed post-execution for anomaly patterns | Sampling logic that is purely random misses correlated error clusters; no feedback path to model improvement |
The sections that follow focus on the implementation mechanics that cut across all five patterns: how to design reviewer workflows that maintain engagement quality, how to prevent automation complacency from eroding the approval gate and escalation ladder patterns, how to build a multi-signal routing signal that actually discriminates between correct and incorrect actions, and how to close the feedback loop so audit findings from the smart sampling pattern feed back into model improvement.
Reviewer Workflow Design: The Infrastructure Most Teams Underinvest In
Reviewers are the scarcest resource in any production HITL system. Unlike model compute, reviewer capacity cannot be scaled by adding infrastructure — it scales with hiring, training, and attention management. Interface quality directly determines how much of that capacity translates into actual oversight versus rubber-stamping.
The most common interface design error is showing reviewers only the flagged action — the purchase order line, the supplier recommendation, the contract clause — stripped of the context that would allow them to evaluate it. A reviewer who sees "Approve PO #48821 for $47,500 to Supplier X" without the underlying requisition, the price benchmark comparison, the supplier risk score, and the contract terms is not performing oversight. They are performing a signature ritual.
Effective reviewer interfaces share four design requirements:
- Full context display: the interface must surface the AI's reasoning, the data inputs that drove the recommendation, the confidence signal breakdown, and any policy rules that were evaluated — not just the output action.
- Specific decision framing: instead of a binary approve/reject button, reviewers should be presented with a targeted question — "Does the quoted price fall within the acceptable range for this commodity category?" or "Does this supplier's risk profile justify sole-source treatment?" Binary gates invite passive approval; specific questions require active evaluation.
- Batch operations with keyboard shortcuts: for escalation ladder and multi-signal routing patterns where volume is moderate, batch review with keyboard navigation reduces per-decision friction without sacrificing engagement quality. Friction reduction should be applied to the interface mechanics, not to the cognitive demand of the decision.
- Explicit correction logging: the interface must make it easy — not optional — to record why a decision was overridden. Free-text rationale fields with structured taxonomy options (price out of tolerance, supplier risk flag, policy exception required) produce training signal. Uncaptured overrides are wasted data.
Automation Complacency: Diagnosing and Structurally Mitigating the #1 Operational Failure Mode
Automation complacency is not a training problem. It is a cognitive load problem that emerges structurally whenever a human is asked to monitor a high-accuracy automated system for extended periods. The pattern is well-documented in aviation — the Air France 447 accident analysis and Parasuraman and Riley's 1997 foundational research both identify the paradox: the more reliable the automated system, the less vigilant the human monitor becomes, and the worse the outcome when the system does fail.
The same dynamic is now appearing in enterprise AI agent deployments. In one documented production case, deploying a blanket review queue for an autonomous procurement agent produced 99.7% approval rates within 48 hours — not because the agent was performing at 99.7% accuracy, but because reviewers had effectively stopped reading. The review queue had become a compliance artifact rather than an oversight mechanism.
High system accuracy makes complacency worse, not better. When reviewers see consistent correctness, their prior for "the AI is right" strengthens with every approval. By the time an error appears, the reviewer's cognitive posture is the opposite of skeptical. This is why complacency mitigation cannot rely on reviewer training alone — training degrades without structural enforcement.
Three structural mitigations address the root cause rather than the symptom:
- Reviewer rotation and shift limits. Review quality drops measurably after extended periods on a single queue. In documented production deployments, review quality declined approximately 40% after two hours of continuous reviewing. Rotating reviewers every 90 minutes and capping shifts at 50 review actions maintains engagement quality without requiring reviewers to sustain attention indefinitely. This is a scheduling and staffing requirement, not a preference.
- Random audit programs. A percentage of actions that fall within autonomous thresholds should be routed to human review without the reviewer knowing which actions were autonomously executed versus flagged for audit. This serves two functions: it generates a ground-truth sample for measuring autonomous decision quality, and it prevents reviewers from developing a mental model of "these are the easy ones." The audit sample does not need to be large — 2-5% of autonomous volume is sufficient for trend detection.
- Active engagement design. Periodic calibration exercises — where reviewers evaluate a set of known-correct and known-incorrect actions and receive feedback on their accuracy — recalibrate reviewer judgment and signal that oversight quality is being measured. These exercises also surface reviewers whose approval rates have drifted toward 100%, which is an actionable management signal rather than a performance assumption.
Multi-Signal Confidence Routing: Why Raw LLM Confidence Scores Fail Procurement AI
The most technically consequential implementation decision in any autonomous procurement AI deployment is how the system determines which actions require human review. Most initial implementations rely on a single signal: the LLM's self-reported confidence score. This approach has a documented and serious reliability problem.
In one production case covering millions of agent tasks, the average LLM confidence score on incorrect actions was 0.87 — well above most deployment thresholds. A confidence-only threshold set at 0.85 missed 68% of errors that actually mattered. More critically, 42% of all errors occurred when the agent reported confidence above 0.90. The errors the system was most wrong about were the ones it was most confident in.
This is not a threshold calibration problem that can be solved by lowering the cutoff. It reflects two independent properties of confidence scoring that must both be measured: calibration (whether stated confidence matches empirical success rates) and discrimination (whether confidence scores actually separate correct from incorrect outputs). A system can pass a calibration check while failing at discrimination — meaning its confidence scores are accurate on average but useless for identifying specific errors. Both properties must be evaluated in your monitoring pipeline, not just one.
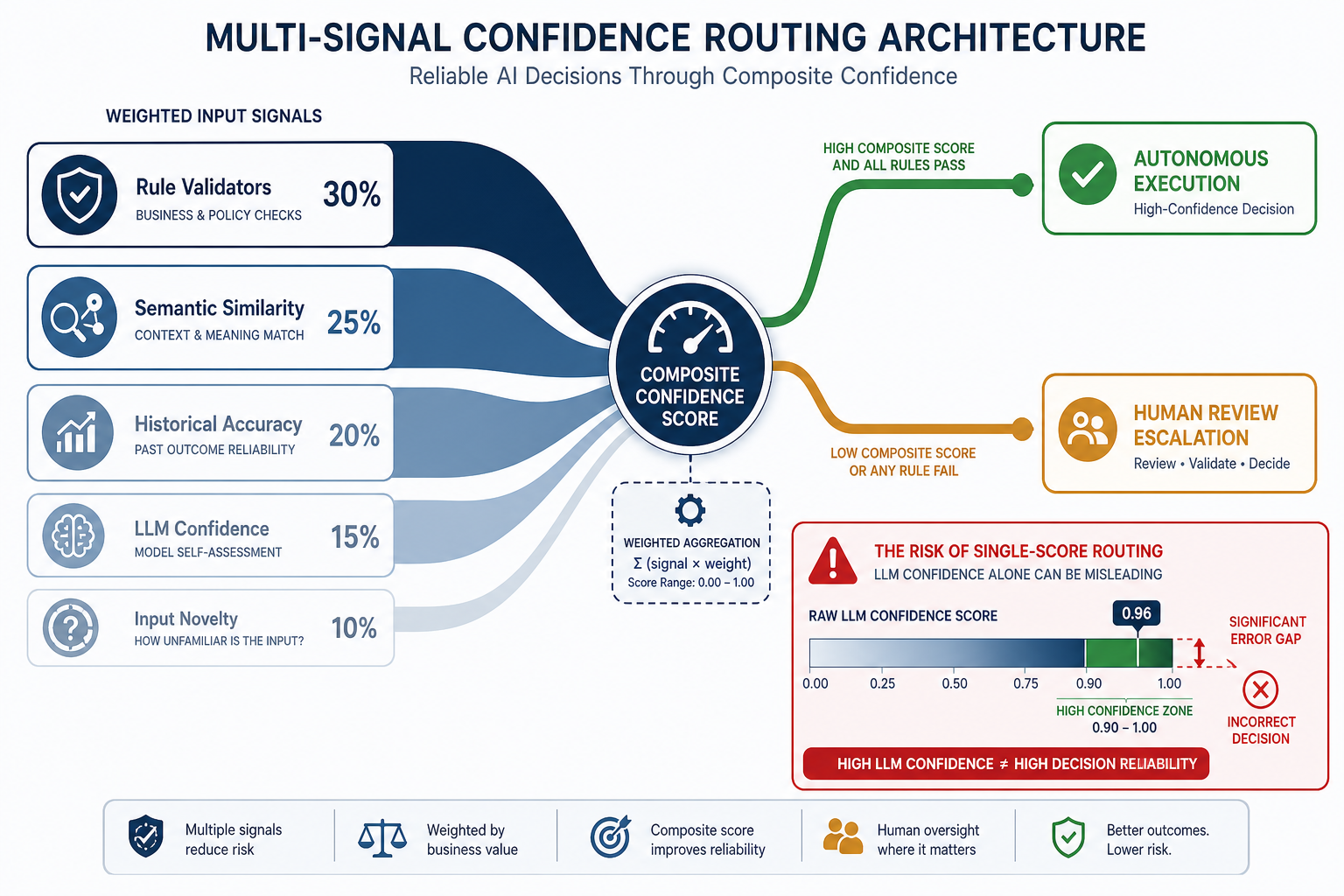
The alternative is a composite routing signal that combines multiple independent signals, each weighted according to its reliability and determinism. A production-tested weighting structure that has demonstrated substantially better discrimination than single-score thresholding assigns weights as follows:
| Signal | Weight | Rationale |
|---|---|---|
| Rule validators | 30% | Deterministic checks against procurement policy rules (spend limits, approved supplier lists, contract terms, regulatory constraints). Binary pass/fail; highest weight because they cannot be wrong. |
| Semantic similarity | 25% | Measures how closely the current action matches historical actions where outcomes are known. High similarity to previously correct actions increases confidence; low similarity flags novelty. |
| Historical accuracy | 20% | The agent's empirical accuracy rate on this specific action type, supplier category, and spend range — derived from logged outcomes, not self-reported. |
| LLM confidence score | 15% | The model's self-reported probability estimate. Deliberately low weight given documented overconfidence in the high-confidence band. |
| Input novelty | 10% | Measures how far the current input deviates from the training distribution. High novelty increases routing to human review regardless of composite score. |
One implementation requirement is non-negotiable: rule validator failures must trigger escalation regardless of composite score. If a proposed action violates a procurement policy rule — even if every other signal is high-confidence — the action routes to human review. The composite score governs the gray zone; hard rules govern the boundaries.
The production outcome from switching to this composite routing approach — reported as directionally illustrative from a practitioner-reported case rather than independently verified research — showed errors caught before execution improving from 32% to 89%, false positives dropping from 41% to 12%, and average review latency dropping from 6.4 hours to 18 minutes. The false positive reduction matters as much as the error detection improvement: a system that routes too many correct actions to human review creates the volume fatigue that drives complacency in the approval gate pattern.
Trust Calibration: Expanding AI Autonomy Thresholds as Performance Data Accumulates
Autonomy thresholds set at deployment are not the correct thresholds for month six. A system that starts with conservative routing — sending 60% of actions to human review — should be routing far less as empirical performance data accumulates and the model demonstrates sustained accuracy across specific action categories. The failure to build a documented calibration process means organizations either leave value on the table by maintaining unnecessary review volume, or expand autonomy informally based on intuition rather than evidence.
Trust calibration is a documented progression, not a one-time governance decision made at deployment. Two primary monitoring signals drive threshold adjustment decisions:
- Escalation rate. The percentage of actions routed to human review. This metric should decline over time as the model improves on high-volume action categories. A flat or rising escalation rate signals either model stagnation or threshold miscalibration — and requires investigation before any autonomy expansion.
- Human override rate. The percentage of escalated actions where the human reviewer changes the AI's recommendation. This metric should stabilize and then decline as the model learns from corrections. A persistently high override rate on a specific action category indicates the model has not generalized from feedback in that domain — autonomy should not be expanded for that category regardless of overall performance.
Threshold expansion decisions should be governed by a cross-functional review body that includes procurement operations, legal or compliance, and the technical team responsible for model performance. The criteria for expansion should be explicit and quantitative: sustained override rates below a defined threshold across a minimum transaction volume, not time elapsed. Time-based expansion assumes improvement that may not have occurred.
| Calibration Stage | Escalation Rate Target | Override Rate Criterion | Expansion Trigger |
|---|---|---|---|
| Initial deployment (months 1–2) | 50–70% of actions reviewed | Baseline measurement only | No expansion; data accumulation phase |
| Early production (months 3–5) | 30–50% of actions reviewed | Override rate stabilizing below 15% | Expand autonomy on action categories with override rate < 10% over 500+ transactions |
| Mature production (months 6+) | 10–25% of actions reviewed | Override rate below 8% on expanded categories | Expand to next spend tier or action category after cross-functional review sign-off |
| Optimized production | < 10% review rate on routine categories | Override rate below 5% on established categories | Ongoing monitoring; expand only with new evidence; maintain conservative posture on novel action types |
One technical requirement that is frequently underspecified: autonomy thresholds must be stored in a centralized, hot-reloadable policy management system — not hardcoded into the agent. When a compliance issue is identified or a model error pattern emerges, the governance team needs to be able to tighten thresholds immediately without requiring an agent redeployment cycle. Systems where thresholds are embedded in code create a governance lag that can span days or weeks during incidents.
Feedback Loop Mechanics: Turning Human Corrections into Model Improvement
A HITL system without a functioning feedback loop is expensive overhead. Reviewers spend time evaluating actions, overriding errors, and documenting corrections — and none of that effort compounds into model improvement. The system costs the same to run in month twelve as it did in month one, and the model makes the same mistakes.
When the feedback loop is built correctly, the opposite dynamic emerges. One practitioner-reported production case showed agent accuracy on high-stakes tasks improving from 76.6% to 91.2% over 14 months, driven primarily by systematic HITL correction data rather than model retraining from scratch. The human review layer became the primary mechanism for continuous model improvement — which is what justifies its ongoing operational cost.
Building a functional feedback loop requires four logging requirements that must be enforced at the interface level, not left to reviewer discretion:
- Action type and context snapshot. Every reviewed action must be logged with the full input state that the agent saw — not just the action output. Without the input context, correction data cannot be used to improve the model's input-to-output mapping.
- Reviewer ID and timestamp. Reviewer identity enables inter-reviewer agreement analysis and allows systematic bias in individual reviewer judgments to be identified and corrected before it contaminates the training signal.
- Decision rationale with structured taxonomy. Free-text rationale fields produce noisy training signal. Corrections should be classified against a structured taxonomy: price out of tolerance, supplier risk flag, policy rule violation, factual error in AI output, context missing, and so on. The taxonomy should be maintained by the policy owner and updated as new error patterns emerge.
- Outcome classification. Once a reviewed action has an observable outcome — the PO was executed and the invoice matched, or the supplier delivered on time, or the contract term was disputed — that outcome must be linked back to the original review decision. Outcome data closes the loop from reviewer judgment to real-world result, which is the ground truth the model needs to improve.
Regulatory Compliance Checkpoint: EU AI Act Article 14 and Procurement AI
For organizations operating in or selling into the European Union, the August 2, 2026 enforcement deadline for EU AI Act requirements on high-risk AI systems is now weeks away from this publication date. Article 14 of the Act requires that high-risk AI systems be designed and developed to allow effective oversight by natural persons — specifically, qualified individuals who can interpret the system's outputs, understand its capabilities and limitations, and intervene, stop, or override the system where appropriate.
For systems that do qualify, the HITL design patterns and reviewer workflow infrastructure described in this guide are directly relevant to Article 14 compliance. Demonstrable human oversight requires more than a review queue — it requires evidence that reviewers have the context, tools, and authority to exercise genuine judgment, and that their interventions are logged and acted upon. A 99.7% approval rate audit log does not demonstrate meaningful oversight; it demonstrates a compliance artifact.
GDPR implications are also relevant for organizations logging reviewer decisions that involve personal data — supplier contact information, employee purchasing behavior, or individual contract terms. Logged reviewer decisions containing personal data are subject to GDPR audit trail and data retention requirements. Legal review of the logging architecture before go-live is advisable for any system operating under both EU AI Act and GDPR jurisdiction.
Governance KPIs: Four Metrics That Indicate HITL Health in Production
Volume-based metrics — transactions processed, time saved, cost per PO — measure system throughput, not oversight quality. A HITL system can process high volume efficiently while the human oversight layer has completely degraded. The four metrics below measure whether the oversight mechanism is actually functioning.
| KPI | What It Measures | Healthy Signal | Intervention Trigger |
|---|---|---|---|
| Error rate on high-stakes tasks | Baseline outcome quality — the percentage of high-stakes actions (above defined spend or risk threshold) that resulted in a measurable error post-execution | Declining trend over time as model improves from feedback | Flat or rising rate signals model stagnation or feedback loop failure |
| Time from error to detection | How quickly the reviewer layer catches failures after they occur — measured from execution timestamp to reviewer flag or audit discovery | Shortening as routing logic improves and audit sampling becomes more targeted | Detection lag exceeding 24 hours on high-stakes errors requires routing threshold review |
| Inter-reviewer agreement rate | The percentage of escalated actions where two independent reviewers reach the same decision | Sustained above 90% within a defined action category | Below 90% signals policy ambiguity — guidelines must be updated, not reviewers retrained |
| Percentage of tasks requiring human review | The share of total autonomous actions routed to human review — the primary indicator of trust calibration progress | Declining over time as model accuracy improves on established action categories | Flat or rising trend signals model stagnation, threshold miscalibration, or feedback loop failure |
The fourth metric — percentage of tasks requiring human review — deserves particular attention as a governance signal. A declining trend over time is the expected outcome of a functioning HITL system: the model improves from feedback, the routing logic becomes more discriminating, and fewer actions require human intervention. A flat or rising trend after the initial deployment period is a diagnostic signal, not an acceptable steady state.
Measurement cadence matters as much as metric selection. Error rate and review percentage should be monitored daily during the first 90 days of production, weekly thereafter. Inter-reviewer agreement should be calculated per action category on a rolling 30-day basis — not as an aggregate that masks category-level policy drift. Time-from-error-to-detection should be reviewed after every identified error event, not on a scheduled cadence, because the detection lag for any individual error is an immediate operational signal.
The operational infrastructure described throughout this guide — reviewer rotation schedules, composite routing signals, centralized policy management, structured correction logging, and calibration progression criteria — is not a set of recommendations to implement when time permits. It is the minimum viable architecture for autonomous procurement AI that maintains genuine human oversight in production rather than generating audit logs that simulate it.
Comments
Join the discussion with an anonymous comment.