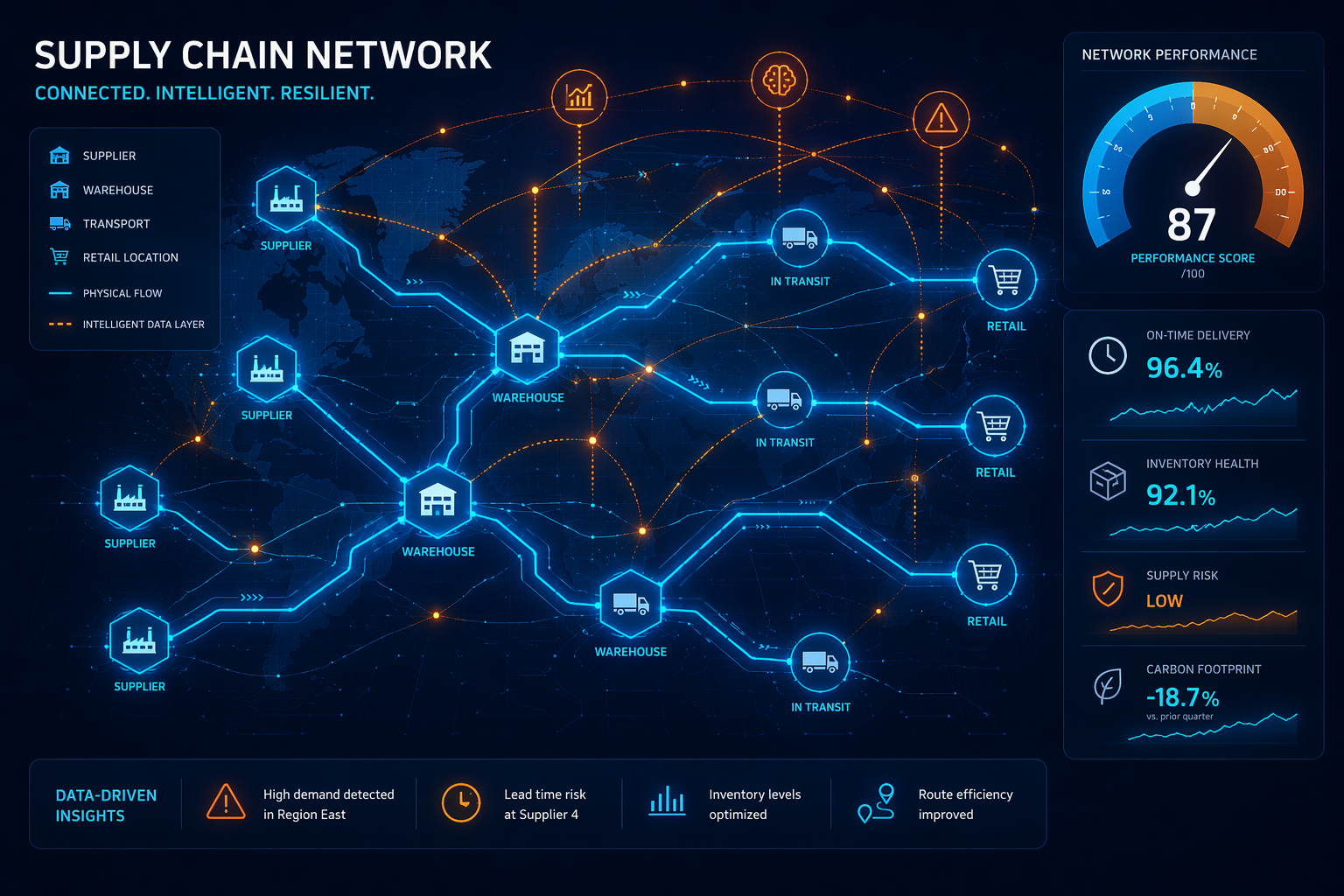
The Deceptive Promise of "Structured" Enterprise Data
Most supply chain leaders believe their data is AI-ready. The ERP is live. The data warehouse is populated. Dashboards refresh every morning. But open any master data table and the cracks appear immediately: the same supplier appears three times under different names, part numbers follow no consistent convention across divisions, and lead time fields still carry values entered manually five years ago.
This is the deception of "structured" enterprise data. It looks organized because it lives in relational tables, but it is fragmented, inconsistent, and stale. When an AI model ingests this data, it does not recognize the duplicates or flag the outdated entries. It treats every row as equally valid and learns patterns from the noise.
Consider a common scenario: a global manufacturer maintains separate ERP instances for its North American and European divisions. The same raw material has different part numbers in each system. A demand forecasting model trained on combined historical data sees two distinct products with independent demand patterns. It doubles the forecast error because it cannot resolve the identity. The model is not wrong. The data is.
The Failure Pattern: Sophisticated AI on Broken Data
The pattern repeats across industries with depressing consistency. An organization invests in a state-of-the-art AI planning platform, allocates budget for model training and tuning, and expects a step-change in forecast accuracy or inventory turns. Six to twelve months later, the project is either abandoned or delivering results far below projections.
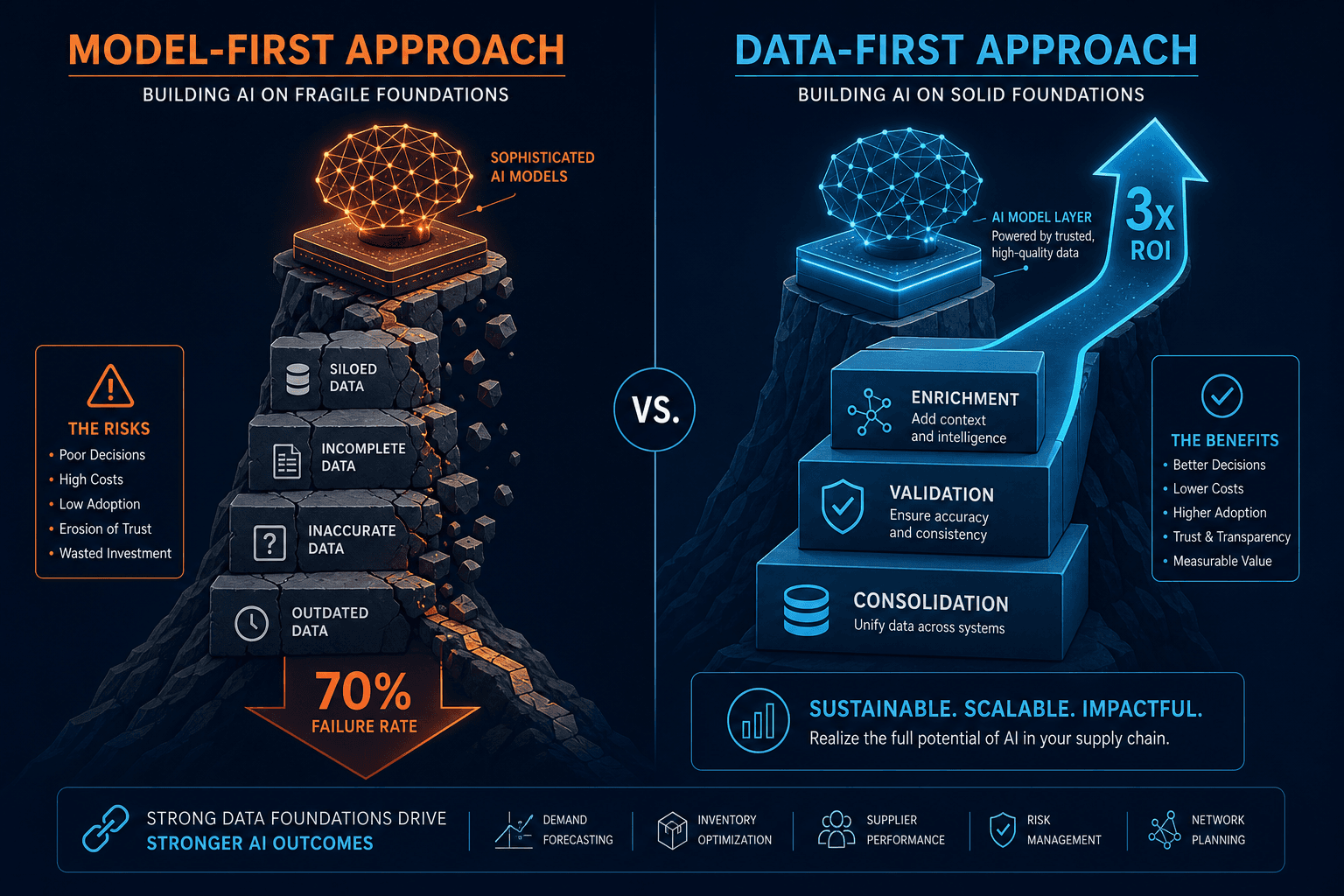
According to data from TraxTech, 70% of AI projects fail due to data quality issues rather than algorithmic limitations. The algorithms are not the bottleneck. The data foundation is. Poor data quality costs organizations an average of $12.9 million annually, with supply chain operations experiencing a disproportionate share of that cost due to the volume and velocity of transactional data they generate.
| Approach | Investment Focus | Failure Rate | Relative ROI |
|---|---|---|---|
| Model-first | Algorithm selection, model tuning, platform licensing | ~70% | Baseline |
| Data-first | Data consolidation, validation, governance, enrichment | Significantly lower | 3x better ROI |
The contrast is stark. Companies that invest in data infrastructure first — consolidating silos, validating master data, enriching with external signals — achieve 3x better AI ROI compared to those that rush into algorithmic solutions. The data-first approach does not delay value; it de-risks the entire investment.
Why AI Amplifies Flawed Data — It Doesn't Fix It
A common misconception among supply chain leaders is that AI can "work around" messy data. The logic sounds plausible: machine learning models are good at finding patterns, so surely they can identify and ignore bad records. This is dangerously wrong.
AI models are pattern matchers. They learn from the data they are given. If the training data contains duplicate supplier records, the model learns that lead times for "Supplier A" and "Supplier A (EMEA)" are different, and it will generate separate predictions for each. If part numbers are inconsistent across divisions, the model treats the same physical item as multiple independent SKUs, inflating safety stock requirements for each.
AI does not clean data. It magnifies data problems at scale. A human planner reviewing a spreadsheet might notice that two supplier names look similar and investigate. An AI model processing millions of rows will never pause to question the duplicates. It will produce confident, wrong predictions and serve them to downstream systems without hesitation.
Consider a concrete example. A distributor with 50,000 SKUs and a 15% duplicate rate in supplier records will see its AI-driven procurement system generate purchase orders based on inflated lead time calculations. The system "learns" that certain materials take longer to arrive than they actually do, triggering early orders that tie up working capital. The cost of the duplicate data compounds across every transaction the model touches.
The Hidden Cost of Legacy Integration
Data quality problems do not exist in isolation. They are deeply entangled with the cost and complexity of integrating legacy systems. When an organization decides to deploy AI across its supply chain, the first technical challenge is not model selection — it is connecting the AI platform to the existing TMS, WMS, and ERP instances.
According to research from The Thinking Company, legacy TMS/WMS integration typically consumes 30–40% of total project cost. Business cases that model only AI model development understate the true investment by 40–60% because they fail to account for the data plumbing required to make the AI work.
| Cost Category | Typical Share of Total Project Cost | Commonly Underestimated? |
|---|---|---|
| AI model development and licensing | 30–40% | No |
| Legacy TMS/WMS integration | 30–40% | Yes — often excluded from initial estimates |
| Data cleaning and master data remediation | 15–25% | Yes — treated as a one-time task rather than ongoing work |
| Change management and training | 10–15% | Yes — frequently cut when budgets tighten |
Integration is expensive precisely because data is messy. Every connection between systems requires mapping fields, reconciling taxonomies, and handling exceptions. A clean, well-governed data environment reduces integration cost because the mappings are simpler and the exceptions are fewer. Organizations that skip the data work upfront pay for it multiple times over in integration overruns.
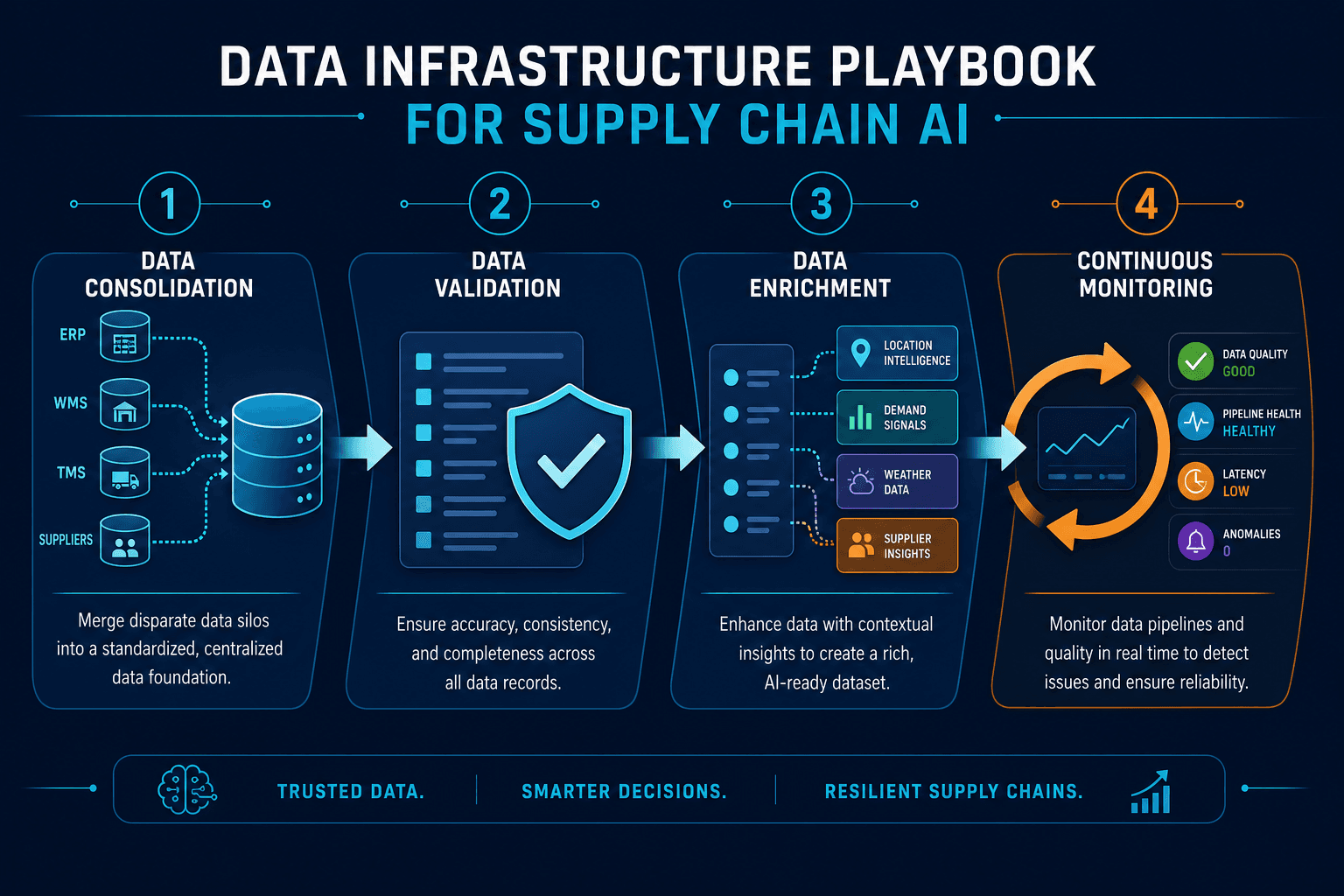
The Data-First Infrastructure Playbook
Fixing the data foundation before deploying AI is not a theoretical ideal. It is a repeatable process with four stages. Organizations that follow this sequence consistently outperform those that skip steps or attempt to parallelize data work with model development.
- Data Consolidation — Merge silos into a unified data layer. This means resolving entity identifiers across ERP instances, standardizing part number conventions, and creating a single source of truth for supplier, customer, and product master data.
- Data Validation — Implement automated checks for completeness, consistency, and freshness. Flag records with missing fields, detect duplicate entries, and timestamp every data point so stale values can be identified and retired.
- Data Enrichment — Augment internal data with external signals: weather data, port congestion indices, commodity price indexes, and geopolitical risk scores. These external signals are often cleaner than internal data because they come from curated sources.
- Continuous Monitoring — Treat data quality as an ongoing operational concern, not a one-time project. Deploy monitoring dashboards that track data freshness, completeness, and anomaly rates. Set alert thresholds that trigger remediation workflows when quality drops below acceptable levels.
The urgency of this playbook is underscored by a sobering statistic from McKinsey: only 53% of supply chain leaders rate their master data quality as "adequate." Nearly half of organizations are operating AI on foundations they themselves acknowledge are insufficient.
For a practical assessment tool, see the CSCO's Data Readiness Checklist for Supply Chain AI Implementation, which provides a stage-by-stage evaluation framework aligned with this playbook.
Model-First vs. Data-First: A Contrast in Outcomes
The difference between model-first and data-first approaches is not subtle. It is the difference between a 70% failure rate and a 3x ROI. The following comparison illustrates how the two paths diverge at each stage of deployment.
| Stage | Model-First Approach | Data-First Approach |
|---|---|---|
| Discovery | Select AI platform and begin model training on existing data | Audit data quality, identify gaps, and plan remediation before any model work |
| Integration | Connect AI platform to existing systems; handle data inconsistencies during integration | Standardize data models across systems first; integration becomes a mapping exercise rather than a firefight |
| Model Training | Train on available data; accept whatever accuracy the data supports | Train on validated, enriched data; achieve higher baseline accuracy from the start |
| Production | Deploy and monitor; discover data issues through model errors in production | Deploy with confidence; monitoring focuses on model drift rather than data quality firefighting |
| Outcome | ~70% failure rate; high integration cost; low trust in outputs | 3x ROI; lower total cost; high stakeholder confidence in AI recommendations |
Trust as the Prerequisite for AI Readiness
Data quality is not just a technical concern. It is the foundation of organizational trust in AI-driven decisions. Supply chain leaders will not delegate inventory replenishment, procurement decisions, or logistics routing to an AI system if they do not trust the data feeding it.
This trust deficit is measurable. According to data from Tradeverifyd, 27% of executives identify fragmented IT and systems integration as the primary barrier to achieving Digital Product Passport readiness — a closely related challenge that requires the same data foundations as AI deployment. When systems do not talk to each other reliably, no one trusts the output.
Compounding the trust problem is the lack of formal AI strategy. Gartner reports that only 23% of supply chain organizations have a formal AI strategy. Without a strategy that explicitly addresses data readiness, organizations drift into model-first deployments by default, and the predictable failure pattern repeats.
Implementation Roadmap with Data Readiness Gating Criteria
The following roadmap provides concrete gating criteria that organizations should meet before progressing to each subsequent stage. These gates prevent the common failure pattern of moving to model training before the data foundation is ready.
| Stage | Gating Criteria | Key Activities | Exit Condition |
|---|---|---|---|
| 1. Data Audit | Executive sponsorship secured; cross-functional data team formed | Inventory all data sources; assess completeness, consistency, and freshness; document known quality issues | Published data quality scorecard with baseline metrics |
| 2. Data Remediation | Data quality scorecard shows <10% critical errors in master data | Resolve duplicate records; standardize taxonomies; implement automated validation rules | Master data accuracy > 90% across all critical entities |
| 3. Data Integration | Master data accuracy sustained above 90% for two consecutive months | Build unified data layer; map fields across systems; establish data refresh cadence | All source systems connected to unified layer with automated data quality checks |
| 4. Model Training | Unified data layer operational with <5% data freshness exceptions | Train AI models on validated data; benchmark against baseline accuracy; iterate on feature engineering | Model accuracy meets or exceeds business case projections on holdout test set |
| 5. Production Deployment | Model accuracy validated; stakeholder review completed; rollback plan documented | Deploy in parallel with existing processes; monitor outputs; establish human-in-the-loop review for exceptions | AI recommendations accepted without override in >80% of routine decisions |
| 6. Continuous Monitoring | Production deployment stable for 90 days | Implement model drift detection; refresh data quality dashboards; schedule periodic master data audits | Data quality and model accuracy maintained within acceptable thresholds for six months |
The most important gate is between stages 2 and 3. Organizations that attempt to build the unified data layer before achieving master data accuracy above 90% will find themselves remediating data issues during integration — the most expensive time to fix them. The discipline of meeting the accuracy threshold first is what separates successful deployments from the 70% that fail.
For a detailed assessment tool that maps your organization against these criteria, refer to the CSCO's Data Readiness Checklist for Supply Chain AI Implementation. It provides the specific metrics and evaluation rubrics needed to operationalize this roadmap.
Comments
Join the discussion with an anonymous comment.