
Why Data Readiness Determines Supply Chain AI Success
Every CSCO who has watched an AI pilot stall in production knows the pattern: the model looked promising in the lab, but once connected to actual ERP, WMS, and TMS data streams, it produced outputs the planning team couldn't trust. The root cause is almost never the algorithm. It is the data.
The numbers are stark. Across industries, 70% of AI projects fail due to data quality issues rather than algorithmic limitations, according to analysis cited by TraxTech. Poor data quality costs organizations an average of $12.9 million annually. Gartner predicts that through 2026, organizations will abandon 60% of AI projects that are not supported by AI-ready data. And in the supply chain domain specifically, a June 2025 Gartner survey of 120 supply chain leaders found that only 23% of organizations have a formal AI strategy in place — meaning most are approaching AI on a project-by-project basis, which risks creating fragmented systems that cannot scale.
The PwC 2026 Digital Trends in Operations Survey, which polled 767 US operations and supply chain leaders, reinforces the urgency: 87% say poor data quality has impacted their organization's ability to achieve value from digital initiatives. Only 30% report significant improvement in data quality and reliability. Meanwhile, 57% have already integrated AI into selected functions — meaning many are deploying AI on top of data foundations they know are weak.
The counter-evidence is equally instructive. Companies that invest in data infrastructure before pursuing AI achieve 3x better AI ROI compared to those that rush into algorithmic solutions. AI amplifies existing data problems — it processes flawed information at scale and speed, turning manageable data issues into operational crises. For supply chain leaders, the message is clear: data readiness is not a prerequisite to be checked off before the "real work" of AI begins. It is the real work.
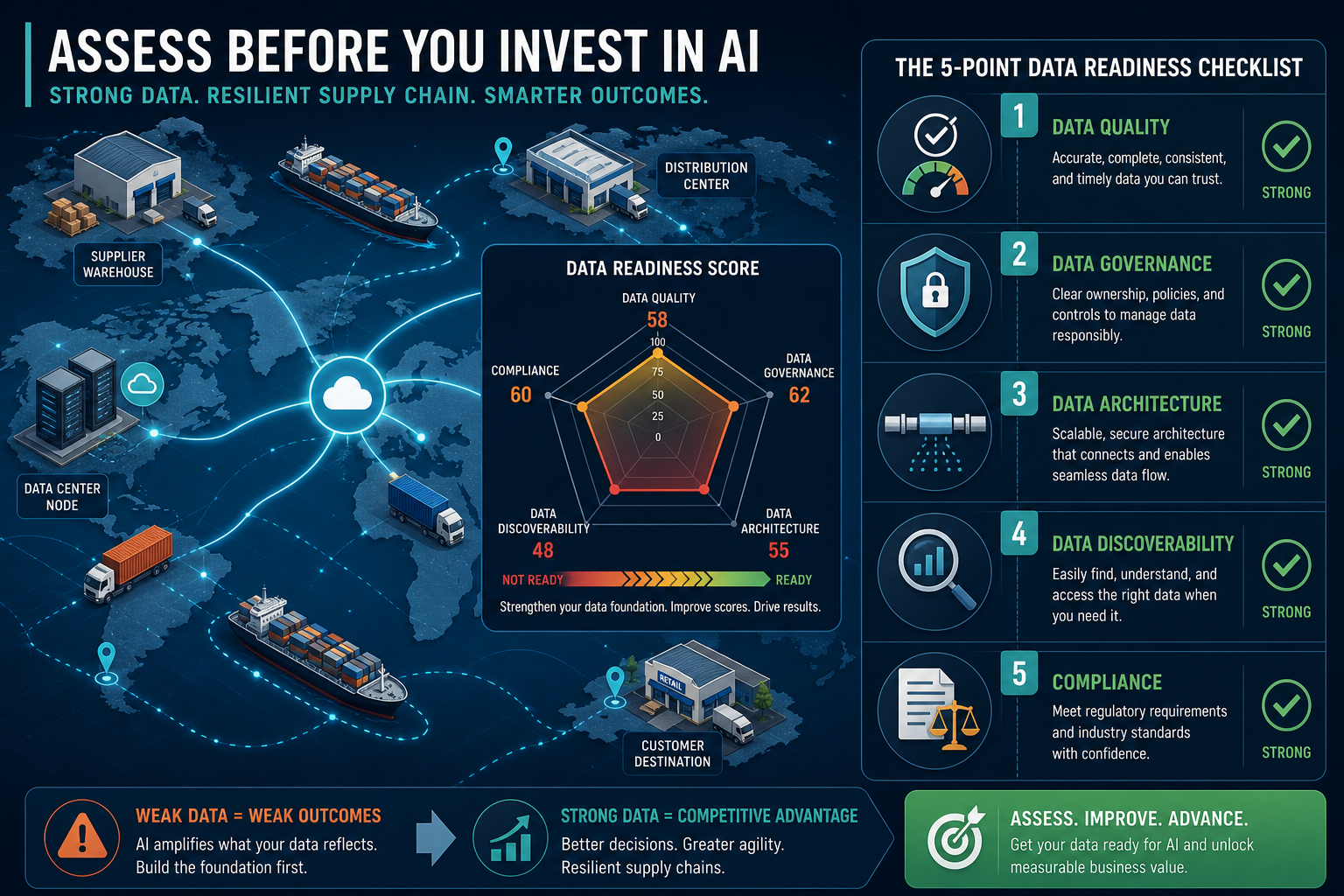
The Five Dimensions of Supply Chain AI Data Readiness
Data readiness for AI is not a single attribute. It is a multi-dimensional state that must be assessed across five distinct domains. These dimensions are synthesized from the Deloitte AIDR (AI Data Readiness) framework, the agility-at-scale data readiness methodology, and Gartner's AI-ready data guidance. Each dimension has specific implications for supply chain contexts.
1. Data Quality
This is the dimension most organizations think they have under control — and are most often wrong about. Traditional data quality metrics (completeness, accuracy, consistency, timeliness) are necessary but not sufficient for AI. As Gartner's AI-ready data research emphasizes, "high-quality data as judged by traditional data quality standards does not equate to AI-ready data." For supply chain AI, data must also be representative — including the errors, outliers, and edge cases that models need to learn from. A clean dataset that excludes supplier delivery delays or demand spikes will produce a model that fails when those events occur.
2. Data Governance
Governance covers who owns the data, how it is defined, how it flows between systems, and how changes are managed. In supply chain environments, master data ownership is often fragmented across procurement, logistics, finance, and operations. The Gartner CSCO Roadmap advises leaders to "secure master data ownership, implement hybrid governance, focus on data quality and accessibility and ensure compliance." Without clear governance, AI models train on inconsistent definitions — one system's "lead time" may exclude customs clearance while another includes it, producing predictions that cannot be reconciled.
3. Data Architecture and Infrastructure
This dimension assesses whether the technical plumbing can support AI workloads at production scale. Key considerations include: data latency requirements (can the model access real-time shipment tracking data, or only batch updates?), integration maturity (are ERP, WMS, TMS, and supplier portals connected through APIs or manual exports?), and storage architecture (can the infrastructure handle the volume and velocity of IoT sensor data from warehouses and containers?). The SAP AI preparation checklist emphasizes the need for clean, accurate, up-to-date data in a multimodal database — a standard that many supply chain organizations have not yet met.
4. Data Discoverability
Discoverability is the dimension most frequently overlooked in readiness assessments. It asks: can the data scientists and engineers building AI models find the data they need, understand its meaning, and trust its provenance? In supply chain organizations, critical data is often buried in spreadsheets on individual analysts' laptops, in legacy system exports, or in PDF supplier communications. Without a cataloged, searchable data inventory, teams waste weeks locating and validating data sources — or worse, build models on incomplete datasets because they did not know better data existed. Atlan's AI readiness research notes that metadata quality will be as important as data quality in the LLM era, a point that becomes critical when considering generative AI applications.
5. Compliance and Ethics
Supply chain AI operates in a regulatory environment that is tightening. Data privacy regulations (GDPR, CCPA), trade compliance requirements, and emerging AI governance frameworks all impose constraints on how data can be used for model training and inference. The Deloitte AIDR framework explicitly includes data ethics and responsibility as a critical dimension. For supply chain use cases, this means ensuring that supplier data, customer demand signals, and logistics partner information are handled in compliance with contractual and regulatory obligations — and that AI-driven decisions (such as automated supplier selection or inventory allocation) can be audited and explained.
Step-by-Step Readiness Assessment Checklist with Scoring
The following checklist is organized by supply chain data type. For each data type, assess readiness across the five dimensions using a 1–5 scale, where 1 means "no capability exists" and 5 means "fully AI-ready." A score of 3 or higher across all dimensions for a given data type indicates readiness for pilot deployment. Scores below 3 signal that remediation is required before investing in AI use cases that depend on that data.
| Data Type | Data Quality (1–5) | Data Governance (1–5) | Architecture (1–5) | Discoverability (1–5) | Compliance (1–5) | Overall Readiness |
|---|---|---|---|---|---|---|
| Master Data (SKU, BOM, customer, location) | Score: ___ | Score: ___ | Score: ___ | Score: ___ | Score: ___ | Avg: ___ |
| Supplier Records (performance, lead times, risk scores) | Score: ___ | Score: ___ | Score: ___ | Score: ___ | Score: ___ | Avg: ___ |
| Inventory Data (stock levels, movements, aging) | Score: ___ | Score: ___ | Score: ___ | Score: ___ | Score: ___ | Avg: ___ |
| Logistics Data (shipment tracking, carrier performance, freight costs) | Score: ___ | Score: ___ | Score: ___ | Score: ___ | Score: ___ | Avg: ___ |
| IoT / Sensor Data (warehouse temp/humidity, container GPS, equipment telemetry) | Score: ___ | Score: ___ | Score: ___ | Score: ___ | Score: ___ | Avg: ___ |
| Demand / Sales Data (POS, orders, forecasts, promotions) | Score: ___ | Score: ___ | Score: ___ | Score: ___ | Score: ___ | Avg: ___ |
For each data type, use the following detailed criteria to assign scores:
- Data Quality: Is the data complete (no critical fields missing)? Is it accurate when spot-checked against source systems? Is it timely (available within the latency window the use case requires)? Are outliers and edge cases preserved rather than scrubbed?
- Data Governance: Is there a named data owner? Are definitions standardized across systems (e.g., same lead time definition in ERP and TMS)? Are change management processes documented? Is there a data dictionary?
- Architecture: Can the data be accessed programmatically (API, data lake, warehouse)? Is the data pipeline documented and monitored? Can the infrastructure handle the volume and velocity required for the target use case?
- Discoverability: Is the data cataloged in a searchable inventory? Are metadata and lineage documented? Can a data scientist find and understand this data within one hour?
- Compliance: Is there a documented data classification for this type? Are access controls in place? Is the data subject to any regulatory or contractual restrictions that affect AI use?
How to Conduct the Assessment: A Four-Step Process
The assessment process, adapted from the agility-at-scale data readiness methodology and the TELUS Digital framework, follows four structured steps. This process ensures that the assessment is grounded in business priorities rather than conducted as a theoretical exercise.
Step 1: Define the Vision and Scope
Before assessing data, the CSCO and the leadership team must define what they are trying to achieve with AI. Is the priority improving demand forecast accuracy for the next S&OP cycle? Reducing inventory carrying costs across three distribution centers? Automating supplier risk scoring for the top 200 suppliers? The vision should be specific enough to bound the data domains that need assessment. A vague "we want to use AI in supply chain" makes it impossible to determine what "ready" means.
Step 2: Prioritize Use Cases via a Data Opportunity Matrix
Not all AI use cases require the same level of data readiness. A Data Opportunity Matrix maps potential use cases against two axes: business value and data readiness. Use cases that score high on both axes are candidates for immediate piloting. Use cases with high business value but low data readiness become priorities for data remediation investment. Use cases with low business value and low readiness should be deferred. This matrix prevents the common mistake of trying to fix all data problems at once — a strategy that is expensive, slow, and often unnecessary.
Step 3: Conduct the Initial Assessment
Using the scoring checklist from the previous section, assess each data type that the prioritized use cases depend on. This is not a one-person exercise. It requires input from data owners (who understand governance and quality), IT/architecture teams (who understand infrastructure and discoverability), and the business users who will consume the AI outputs (who understand what "good enough" looks like for their decisions). The assessment should be conducted as a structured workshop, not as a survey sent by email.
Step 4: Analyze Gaps and Build a Remediation Plan
For each data type where the average score falls below 3, identify the specific gaps. Is the issue that master data lacks a governance owner? That logistics data is only available in weekly batch exports? That supplier records are scattered across procurement spreadsheets with no discoverability? Each gap should be assigned an owner, a remediation approach, and a target timeline. The remediation plan should be sequenced according to the Data Opportunity Matrix — fix the data that unlocks the highest-value use cases first.
Maturity Levels for Supply Chain AI Data Readiness
The agility-at-scale framework, aligned with the AI-REAL and DCO maturity models, defines five levels of data readiness maturity. Understanding where your organization sits on this spectrum helps set realistic expectations for what AI can achieve and how quickly.
| Level | Label | Characteristics | Supply Chain Implications |
|---|---|---|---|
| 1 | Aware | Data exists in silos. No formal governance. Quality is unknown. No catalog or discoverability. | AI is not feasible. Any model built will produce unreliable outputs. Focus on building awareness and securing executive sponsorship for data investment. |
| 2 | Reactive | Data quality is addressed when problems arise. Some governance exists in specific domains. Basic integration between key systems. | Limited pilot potential for narrow, well-scoped use cases with high data maturity in a single domain (e.g., demand forecasting using clean POS data). |
| 3 | Proactive | Data quality is monitored. Governance is defined for critical data domains. Architecture supports batch and near-real-time access. Basic catalog exists. | Minimum level for scaling from pilot to production. Organizations at Level 3 can run multiple AI use cases in parallel with acceptable confidence in outputs. |
| 4 | Managed | Data quality is measured and continuously improved. Governance is enterprise-wide. Architecture supports real-time streaming. Full data catalog with lineage. | AI can be deployed at scale across planning, logistics, procurement, and warehouse operations. Models can be retrained and deployed rapidly as conditions change. |
| 5 | Optimizing | Data readiness is automated and self-healing. AI governs data quality. Metadata is treated as a first-class asset. Full compliance automation. | The organization can pursue advanced AI use cases including autonomous planning, agentic AI, and real-time control tower operations with minimal human intervention. |
Most supply chain organizations today operate at Level 1 or Level 2. The Gartner survey finding that only 23% have a formal AI strategy is consistent with this assessment — organizations at Level 1 or 2 rarely have the data foundation to justify a formal strategy. The goal for most organizations in 2026 should be to reach Level 3 within 12–18 months for the data domains that support their highest-priority use cases.
Implementation Roadmap: From Assessment to Scale
Moving from assessment results to production AI deployments requires a phased roadmap. The following four-phase approach is adapted from the Gartner CSCO Roadmap, the Spinnaker SCA practitioner methodology, and the agility-at-scale implementation guidance.
Phase 1: Foundation (Months 1–3)
- Complete the readiness assessment across all five dimensions for the data types supporting your top 2–3 prioritized use cases.
- Secure master data ownership. The Gartner CSCO Roadmap identifies this as the first essential action. Without a single accountable owner for each critical data domain, governance improvements will stall.
- Establish a data governance council with representation from supply chain, IT, finance, and procurement. Define data ownership, stewardship, and decision rights.
- Begin documenting a data dictionary for the prioritized data domains. This is the foundation of discoverability.
Phase 2: Remediation (Months 4–8)
- Address the highest-impact gaps identified in the assessment. For most organizations, this means improving data quality in master data and establishing consistent governance for supplier and inventory data.
- Implement data quality monitoring for the prioritized data domains. The goal is to move from reactive (Level 2) to proactive (Level 3) quality management.
- Build or improve the data pipeline architecture to support the latency requirements of your target use cases. This may mean moving from batch exports to API-based integration or establishing a data lake.
- Follow the Spinnaker SCA methodology: normalize transactional versus design data (they "don't talk to each other naturally"), and iterate through build-validate-refine cycles rather than aiming for perfection in one pass.
Phase 3: Pilot (Months 9–12)
- Launch the first AI pilot using the data domains that achieved Level 3 readiness. The pilot should be scoped narrowly — one function, one use case, one measurable KPI.
- Establish model monitoring from day one. Track not just model accuracy but also data drift — changes in the underlying data that degrade model performance over time.
- Document everything. As the Spinnaker SCA guide emphasizes, "automate, document, and build a model that outlives you." The pilot should produce reusable data pipelines, governance documentation, and validation protocols.
Phase 4: Scale (Months 13–24)
- Expand the data readiness assessment to additional data domains and use cases, following the same four-step process.
- Invest in the data catalog and metadata management infrastructure needed to sustain discoverability at scale. Atlan's research notes that metadata quality will be as important as data quality in the LLM era.
- Move toward the Run-Grow-Transform framework recommended by Gartner: run the existing AI portfolio reliably, grow it by adding new use cases, and transform the operating model to embed AI-driven decision-making into core processes.
- Reassess maturity level annually. The goal is to move the organization from Level 3 to Level 4 across critical data domains within 24 months.

How Generative AI Changes the Readiness Calculus
Generative AI — particularly retrieval-augmented generation (RAG) — introduces a different set of data readiness priorities compared to traditional predictive ML models. For CSCOs evaluating GenAI use cases such as automated supplier contract analysis, chatbot-based supply chain querying, or generative demand scenario planning, the readiness assessment must account for three additional factors.
Retrieval Corpus Quality Replaces Dataset Quality
In traditional ML, the model trains on a labeled dataset. In RAG-based GenAI, the model retrieves relevant documents from a corpus at inference time and generates responses based on that retrieved context. This shifts the readiness focus from dataset quality to corpus quality. The questions become: Is the corpus comprehensive (does it cover all relevant supplier contracts, logistics agreements, and planning documents)? Is it current (are expired contracts or outdated rate tables excluded)? Is it well-structured (can the retrieval system find the right document quickly)?
Metadata Quality Becomes a First-Class Concern
A RAG system's retrieval accuracy depends on how well documents are indexed and tagged. If a supplier contract is not tagged with the correct supplier ID, contract date, and governing terms, the retrieval system may return the wrong document — or no document at all. This makes metadata quality as important as data quality, a point emphasized by Atlan's AI readiness research. Organizations that have invested in data catalogs and metadata management will have a significant advantage in deploying GenAI use cases.
Hallucination Governance Requires Validation Gates
Generative models can produce confident-sounding but factually incorrect outputs — a phenomenon known as hallucination. In supply chain contexts, a hallucinated supplier lead time or inventory count could trigger incorrect planning decisions. Mitigating this risk requires validation gates: automated checks that compare GenAI outputs against trusted data sources before the outputs are used in decision-making. This is not a data readiness issue in the traditional sense, but it is a data infrastructure issue — the validation gates need access to the same trusted data sources that the readiness assessment evaluates.

For CSCOs, the message is consistent across both traditional ML and GenAI: data readiness is the decisive factor in AI success. The frameworks, checklists, and maturity models in this guide provide a structured path from assessment to production. The organizations that invest in data readiness first — and resist the pressure to skip ahead to model deployment — will be the ones that achieve the 3x ROI advantage that data-first companies consistently report.
Comments
Join the discussion with an anonymous comment.