How to Use This Record
This is a use-case library record, not a general reference. It answers a specific question: for a given procurement use case, which NLP technique layer applies, under which conditions, and what happens when those conditions are not met?
If you need background on how the NLP technique stack works — OCR preprocessing, named entity recognition, clause classification, deviation scoring, and LLM-based generation — start with the AI Contract Intelligence and NLP in Procurement Automation reference article before engaging with this mapping. This record assumes familiarity with those technique definitions and does not restate them.
The primary content object here is a set of structured matrices — technique layer by applicability condition, contract type by NLP layer, and procurement lifecycle stage by technique. Use them as decision tools when sequencing a deployment or evaluating whether a specific technique layer is ready to activate for a given use case.
Technique Layer Capability Matrix: Applicability Conditions by Layer
The five NLP technique layers used in contract intelligence are not interchangeable. Each has a distinct applicability profile — specific use cases it serves, document and data conditions required for reliable output, predictable failure modes when those conditions are absent, and human-in-the-loop (HITL) governance implications specific to that technique.
| Technique Layer | Primary Use Cases | Required Conditions | Failure Mode When Conditions Absent | HITL Governance Implication |
|---|---|---|---|---|
| NER Field Extraction | Metadata population (parties, dates, notice periods, governing law, payment terms, liability caps); contract repository indexing; renewal date tracking | Native-digital or high-quality OCR output; consistent field placement across document population; single-document scope (not cross-document family resolution) | Accuracy degrades on scanned documents with formatting artifacts, embedded tables, and conditional renewal clauses; cross-document families (master + amendment) produce field-level accuracy without contextual accuracy | High-risk fields (renewal dates, notice periods, financial caps, parent-child relationships) require human review before triggering alerts, payments, or reporting; blank fields are safer than wrong fields |
| Clause Classification | Contract type identification; clause library tagging; risk category assignment; clause presence/absence auditing across a portfolio | Sufficient volume of structurally consistent contracts; clause structure that resembles training corpora (standard commercial forms); document language matching model training language | Classification accuracy degrades on heavily negotiated SOWs and enterprise agreements where clause structure departs from standard commercial forms; non-English documents below fine-tuning volume threshold produce unreliable output | Confidence scoring should gate automated classification; human review required for novel clause structures and for any classification that triggers downstream risk scoring or compliance action |
| Obligation Extraction | Post-award commitment tracking (delivery milestones, payment schedules, compliance checkpoints, termination notice periods); rebate trigger identification; SLA monitoring setup | Post-award operational context; structured, non-conditional obligation language; integration connecting contract data to operational performance data; digitized contracts with quantifiable obligations | Conditional obligations ('subject to,' 'provided that,' 'unless otherwise agreed') defeat automated extraction — the extracted obligation omits its governing condition; vague SLA language ('reasonable efforts,' 'best efforts') cannot be converted to trackable thresholds regardless of technique maturity | Legal review of AI-extracted commitments before enforcement action; mandatory human review above defined contract value thresholds; quarterly sampling audits recommended |
| Clause Deviation Scoring | Third-party paper review against preferred positions; negotiation risk flagging; playbook compliance auditing; automated redline suggestion | Documented legal playbook configured into the platform; playbook current with applicable law and internal risk policy; sufficient contract volume to validate deviation scoring against known outcomes | If the playbook is absent, the technique cannot function — there is no preferred position to compare against. If the playbook is stale (not updated for legal or policy changes), the system systematically recommends now-incorrect positions, creating risk the organization believes it has already managed | Reviewers make final call on all flagged deviations; playbook governance process required (owner, update cadence, change log); deviation scoring outputs should not auto-approve or auto-reject without human decision |
| LLM-Based Summarization / Generation | Executive contract summaries; clause drafting assistance; negotiation position generation; Q&A over contract corpus | Highest governance maturity of all five layers; retrieval-augmented generation (RAG) architecture preferred over base LLM to ground outputs in actual contract language; hallucination detection and confidence thresholds configured | Hallucination risk is structurally distinct from discriminative NLP failure modes — a hallucinated summary or generated clause can be plausible-sounding but factually wrong in ways that are not immediately detectable without human review; RAG reduces but does not eliminate this risk | All generative outputs require human review before use in negotiation, execution, or reporting; confidence scoring and mandatory review thresholds are not optional at this layer; governance requirements are higher than for any discriminative technique |
Contract Type Applicability Conditions
Different contract types present different NLP applicability profiles across the five technique layers. The variation is driven by structural consistency, clause standardization, document complexity, and the degree to which the contract is negotiated away from standard commercial forms.
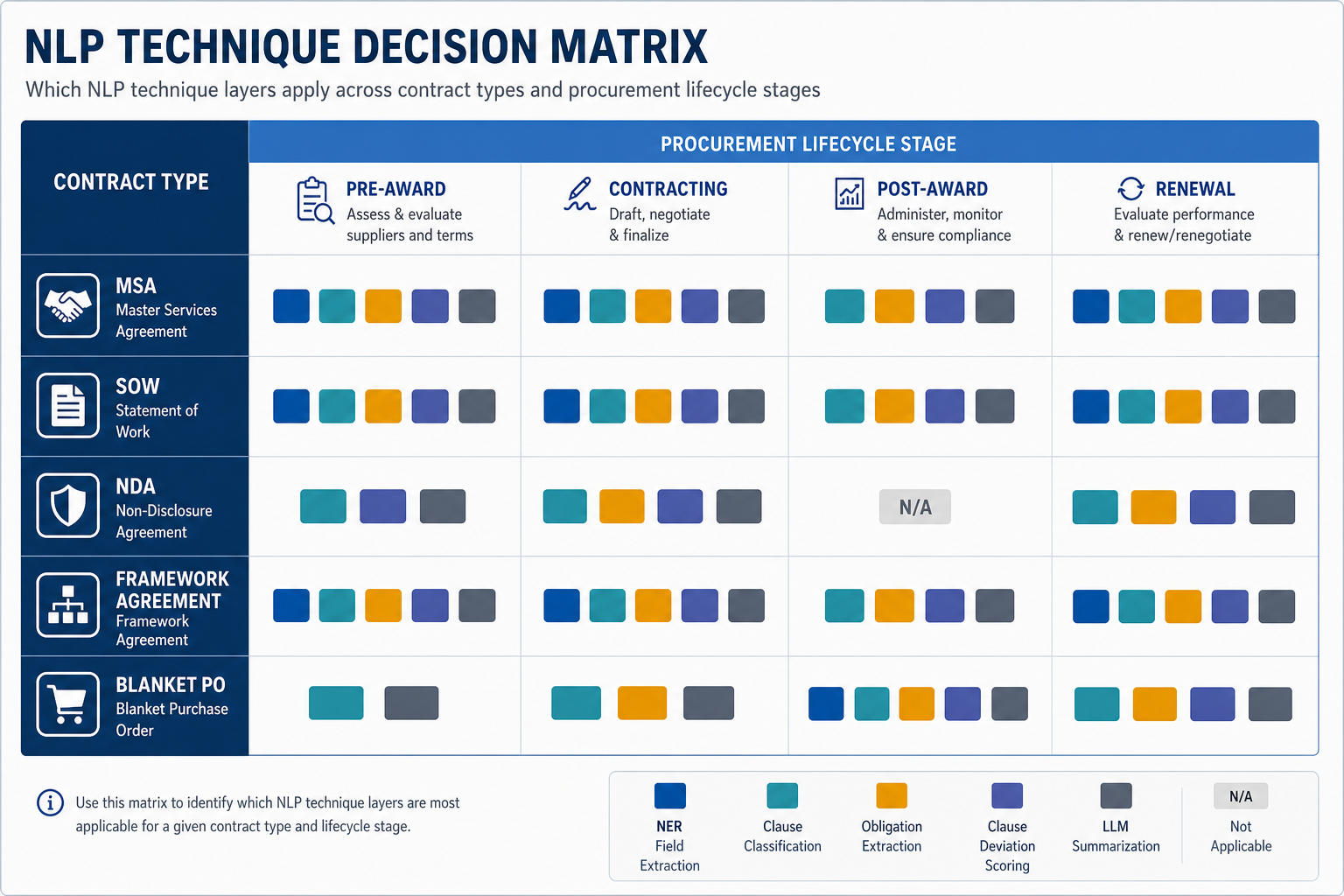
| Contract Type | NER Extraction | Clause Classification | Obligation Extraction | Clause Deviation Scoring | LLM Summarization |
|---|---|---|---|---|---|
| NDA | High reliability — limited field set, standardized structure, native-digital in most enterprise workflows | Highest reliability of all contract types — NDAs are structurally consistent and well-represented in training corpora | Limited applicability — NDAs contain few trackable performance obligations; confidentiality obligations are structural, not operational | Applicable where playbook exists — NDAs are a common starting point for playbook configuration due to structural consistency | Applicable with governance controls — low-stakes starting point for LLM summarization pilots |
| Standard MSA | High reliability for standard fields; degrades on complex indemnification carve-outs and cross-referenced schedules | High reliability on standard commercial MSA structures; degrades on heavily negotiated versions with non-standard clause organization | Applicable for payment terms, liability caps, and notice periods — requires non-conditional language | Applicable where playbook exists — MSAs are the primary use case for playbook-driven deviation scoring | Applicable with governance controls — summarization of standard MSA terms is a common production use case |
| SOW (Statement of Work) | Moderate reliability — SOWs often contain embedded tables, milestone schedules, and variable structures that reduce NER accuracy | Lower reliability — SOWs are structurally heterogeneous and frequently negotiated into non-standard clause arrangements that depart from training corpora | Highest operational value but highest extraction difficulty — deliverable milestones and payment schedules are the target, but conditional language ('upon client acceptance,' 'subject to change order') is pervasive | Applicable only with SOW-specific playbook configuration — generic MSA playbooks do not transfer reliably to SOW structures | Applicable but hallucination risk is higher on complex, multi-milestone SOWs where generative outputs may conflate milestone conditions |
| Framework Agreement | Moderate reliability on core terms; low reliability on pricing schedules and volume commitment tables embedded as attachments | Moderate reliability on framework body; schedule and attachment parsing requires specialized configuration beyond generic clause classification | High-value use case (pricing escalators, volume commitments, rebate triggers) but requires structured schedule parsing that generic NER models do not handle reliably | Applicable where playbook covers framework-specific terms — pricing escalator and volume commitment positions must be explicitly configured | Applicable for executive summaries of core terms; schedule and attachment summarization requires grounding in retrieved schedule content via RAG |
| Blanket PO | Moderate reliability for standard PO fields; degrades on complex pricing schedules, item-level conditions, and amendment histories | Lower applicability — blanket POs are often structured as transactional documents rather than clause-organized agreements | Applicable for delivery commitment and pricing escalator monitoring — same structured schedule parsing prerequisite as framework agreements | Limited applicability — playbook-driven deviation scoring is less commonly configured for PO formats; applies where PO terms are negotiated against a standard template | Limited applicability — LLM summarization adds less value for transactional PO formats than for multi-clause agreements |
NDAs and standard MSAs represent the highest-reliability starting point for clause classification because their structural consistency aligns with the commercial contract corpora on which most classification models are trained. Heavily negotiated enterprise agreements and bespoke SOWs sit at the opposite end of the spectrum — their clause structures frequently depart from training data in ways that produce silent misclassification rather than explicit errors.
Procurement Lifecycle Stage Mapping
The procurement lifecycle stage is the primary sequencing determinant for NLP technique selection. Different stages have different information needs, different document availability profiles, and different organizational contexts that affect which techniques are applicable and which are misapplied.
| Lifecycle Stage | Applicable Technique Layers | Conditions That Must Hold | Common Misapplication |
|---|---|---|---|
| Pre-Award / Sourcing | NER field extraction (from existing contracts for benchmarking); clause classification (for contract mining — surfacing renewal dates, auto-renewal clauses, pricing escalators, rebid triggers from incumbent agreements) | Centralized contract repository with sufficient incumbent agreement coverage; native-digital or high-quality OCR output; single-document scope for extraction | Applying obligation extraction at pre-award stage — obligations are post-signature commitments and have no operational context to monitor against before award |
| Contracting / Negotiation | Clause deviation scoring (third-party paper review against playbook); clause classification (clause presence/absence audit); LLM-based generation (clause drafting assistance, preferred language suggestion) | Documented legal playbook configured and current; playbook covers the contract type being negotiated; LLM generation layer has governance controls and mandatory human review | Applying obligation extraction during negotiation — obligations are not yet operative and the monitoring integration prerequisite cannot be met before execution |
| Post-Award / Compliance | Obligation extraction (commitment tracking, milestone monitoring, SLA compliance setup); NER extraction (populating compliance monitoring fields); clause classification (categorizing obligations by type for monitoring workflow routing) | Integration connecting contract data to operational performance data; non-conditional obligation language in the contract; digitized contracts with quantifiable obligations; post-execution operational context | Attempting automated SLA compliance monitoring on vague obligation language ('reasonable efforts,' 'commercially reasonable') — these cannot be converted to trackable thresholds regardless of technique maturity |
| Renewal / Renegotiation | NER field extraction (renewal dates, notice deadlines, auto-renewal triggers — highest-value use case with lowest prerequisites); clause classification (identifying terms due for renegotiation); LLM summarization (executive summary of expiring agreement for renegotiation briefing) | Accurate extraction of renewal date fields with HITL review for conditional renewal logic; clause classification reliability sufficient for the contract type; LLM summarization governance controls in place | Assuming NER extraction of renewal dates is reliable without HITL review for amendments — amendments frequently change notice deadlines in ways that automated extraction misses, particularly when timing logic is conditional on prior-term events |
The renewal stage has the highest applicability ceiling for standard NER extraction with the lowest organizational prerequisites. Contract mining — reviewing existing agreements to surface renewal windows, auto-renewal clauses, pricing escalators, and rebid triggers — is consistently rated among the highest-impact NLP contract intelligence use cases relative to implementation complexity.
Organizational Prerequisites: What Technology Cannot Substitute
Certain prerequisite conditions for NLP contract intelligence are organizational, not technological. No platform configuration can substitute for them. Three organizational prerequisites are technique-specific and commonly absent:
- The playbook prerequisite for clause deviation detection. Playbook-driven deviation scoring only functions when a documented legal playbook — preferred positions, fallback positions, and escalation thresholds for each clause type — has been configured into the platform. This is an organizational artifact that procurement legal teams must create, maintain, and govern. It is not a feature the platform provides. Most procurement organizations do not have a configured, current playbook at the clause-type level required for automated deviation scoring. The absence of a playbook does not mean the technique is partially applicable — it means the technique cannot function.
- Playbook drift risk. When a playbook exists but is not kept current with changes in applicable law, regulatory guidance, or internal risk policy, the deviation scoring system continues recommending positions that the organization has already moved away from. This creates a specific failure mode: the organization believes it has managed a risk category through automated review, but the AI is consistently applying outdated positions. Playbook governance — owner assignment, update cadence, change log — is a prerequisite for sustained deployment of clause deviation scoring, not a post-deployment optimization.
- The integration prerequisite for post-award compliance monitoring. Obligation extraction produces a structured list of commitments from contract text. Converting that list into a functioning compliance monitoring workflow requires integration connecting contract data to operational performance data — delivery confirmations, payment records, milestone completion signals, audit outputs. Without that integration, obligation extraction produces a static list that requires manual tracking, which is operationally equivalent to a contract abstract. The compliance monitoring value case depends entirely on the integration layer being in place.
For readers assessing their organization's readiness to activate specific technique layers, the Data Readiness Assessment for AI Procurement Automation implementation guide covers the broader data and system prerequisites in structured checklist form. The organizational prerequisites above are distinct from data readiness — they are governance and process conditions that must be addressed independently of data quality.
Conditions Where NLP Is Not the Right Technique
Across all five technique layers, there are cross-cutting conditions under which NLP contract intelligence will systematically underperform regardless of platform maturity or configuration quality. These are not edge cases — they are predictable failure conditions that apply to recognizable segments of most enterprise contract portfolios.
- Conditional obligations. Obligation extraction requires structured, non-conditional obligation language to function reliably. Most supplier contract portfolios contain a significant share of obligations qualified by conditions ('subject to client acceptance,' 'provided that regulatory approval is obtained,' 'unless otherwise directed in writing'). When the governing condition is extracted without its qualifier, the resulting obligation record is wrong — not incomplete, but affirmatively incorrect. Automated obligation tracking built on conditional extraction creates enforcement and compliance risk. Most supplier contract portfolios do not meet a non-conditional obligation language standard across more than 40–60% of their agreements.
- Cross-referenced document families. NLP extraction operates at the document level. When a contract consists of a master agreement, one or more amendments, and associated SOWs or schedules, field-level accuracy on each document does not equal contextual accuracy across the family. An amendment changing a liability cap is not automatically connected to the parent agreement's cap field. An SOW specifying delivery terms that supersede the MSA's standard terms is not automatically recognized as controlling. The result is that extracted metadata from individual documents can be individually correct and collectively misleading. This failure mode is structural, not a function of model quality.
- Non-English language portfolios below fine-tuning volume threshold. NLP models trained on English commercial contract corpora do not transfer reliably to other languages without fine-tuning on sufficient domain-specific data in the target language. For organizations with multinational supplier portfolios, non-English contracts below the volume threshold required to fine-tune or validate models should not be processed through the same NLP pipeline as English-language agreements. Applying English-trained models to non-English contracts without validation produces extraction and classification outputs that appear complete but carry unverified accuracy.
- Vague SLA language. Automated compliance monitoring requires quantifiable thresholds. SLA language using 'reasonable efforts,' 'best efforts,' 'commercially reasonable,' or similar constructions cannot be converted to trackable compliance metrics regardless of which technique layer is applied. This is a contract drafting condition, not a technology limitation — and it cannot be resolved by the NLP system. Organizations seeking to activate post-award compliance monitoring should audit their contract portfolio for quantifiable vs. qualitative SLA language before configuring monitoring workflows.
Deployment Sequencing Implications
The applicability conditions mapped above translate directly into a sequencing logic for technique layer activation. The sequencing is not arbitrary — it reflects which layers have the broadest applicability, the lowest organizational prerequisites, and the most predictable failure modes when conditions are not yet met.
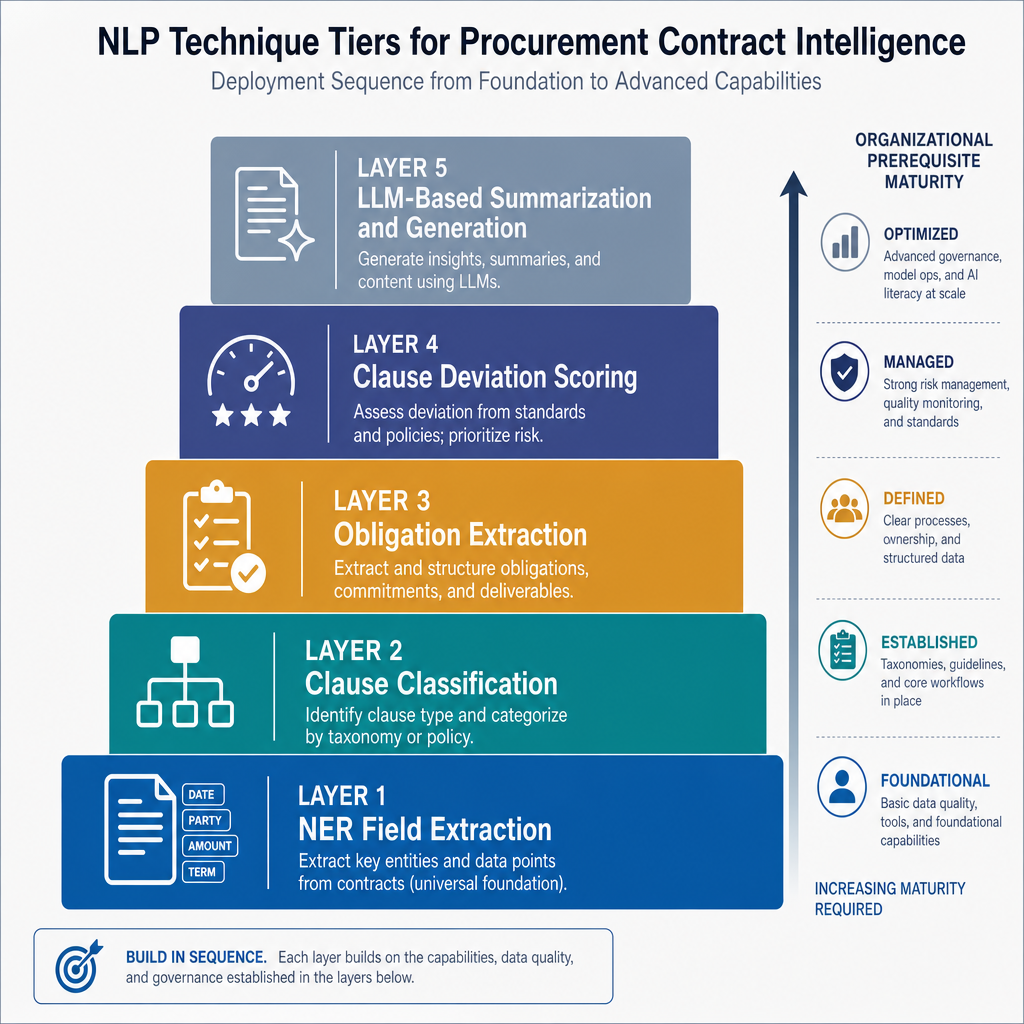
- NER field extraction first, for all contract types and stages. This is the universally correct starting layer. It has the broadest applicability across contract types, the lowest organizational prerequisites, and the most actionable immediate value (renewal date tracking, notice period alerts, repository population). HITL review for high-risk fields should be configured from the start, not added later. Accuracy validation against a sample of the actual contract population — not vendor benchmark data — should precede production deployment.
- Clause classification second, conditional on contract volume and structural consistency. Activate clause classification after NER extraction is validated and stable. The prerequisite is a sufficient volume of structurally consistent contracts in the target contract type. Start with NDAs and standard MSAs, where reliability is highest. Do not extend to heavily negotiated SOWs or enterprise agreements without accuracy validation on a representative sample of those specific document types.
- Obligation extraction third, only in post-award context. Obligation extraction is a post-award technique. Activate it only after the operational integration connecting contract data to performance data is in place. Audit the target contract population for conditional obligation language before configuring monitoring workflows — the share of agreements with non-conditional, quantifiable obligations determines the realistic coverage of this technique layer.
- Clause deviation scoring fourth, conditional on playbook existence and currency. Do not activate this layer without a documented, current legal playbook configured into the platform. The playbook prerequisite is an organizational condition that must be addressed before technology configuration begins. Establish a playbook governance process — owner, update cadence, change log — as part of the activation work, not as a post-deployment task.
- LLM-based summarization and generation last, with the highest governance maturity requirement. This layer introduces hallucination risk that discriminative NLP techniques do not. Retrieval-augmented generation architectures reduce but do not eliminate this risk. All generative outputs require mandatory human review before use in negotiation, execution, or reporting. Confidence scoring and review thresholds should be configured before any production use. This layer should not be activated until HITL governance for lower layers is functioning reliably.
This sequencing logic applies regardless of which vendor platform is used. The technique layer prerequisites are organizational and data conditions — they do not vary by platform. Vendor platforms may bundle multiple layers under a single product offering, but the applicability conditions for each layer remain independent of how the platform is packaged.
Comments
Join the discussion with an anonymous comment.