The Default Problem: How Min-Max Became Everyone's Starting Point
Most enterprise inventory systems ship with min-max replenishment pre-configured. When a planner joins an organization, the parameters are already there—a floor, a ceiling, a trigger. The assumption embedded in that configuration is that whoever set it up made a deliberate choice. In practice, that assumption is almost always wrong.
Min-max rules are ERP defaults, not design decisions. They were set during implementation, often by consultants optimizing for go-live speed rather than inventory performance, and they persist for years without review. Planners learn to work around them—expediting orders, manually adjusting parameters, building informal buffers—rather than questioning the policy architecture itself.
This is an organizational inertia problem, not just a technical one. The ERP system treats min-max as a sensible default. Planners treat inherited parameters as baseline truth. Leadership sees inventory as a cost lever rather than a policy governance question. The result is that replenishment policy selection—which policy type to use for which SKU segment—never becomes a deliberate decision. It defaults by omission.
The inertia compounds after AI tools are deployed. Organizations invest in demand forecasting platforms or inventory optimization software, then continue routing replenishment signals through the same min-max rules they've always used. The AI improves the forecast; the replenishment policy ignores the improvement. Planners who distrust model-generated parameters revert to familiar thresholds. The technology investment produces partial returns because the policy architecture underneath it was never addressed.
The framework in this guide addresses that gap. It treats replenishment policy selection as a deliberate, recurring governance decision—not a configuration artifact inherited from ERP implementation.
How Each Policy Type Works: Governing Assumptions, Not Just Definitions
The meaningful difference between min-max, statistical, and ML-based replenishment policies is not what they do mechanically—it is what they assume about the demand environment they operate in. Choosing the wrong policy for a given SKU cluster is not a configuration error; it is a structural mismatch between the policy's assumptions and reality.
Min-Max: Static Threshold Triggers
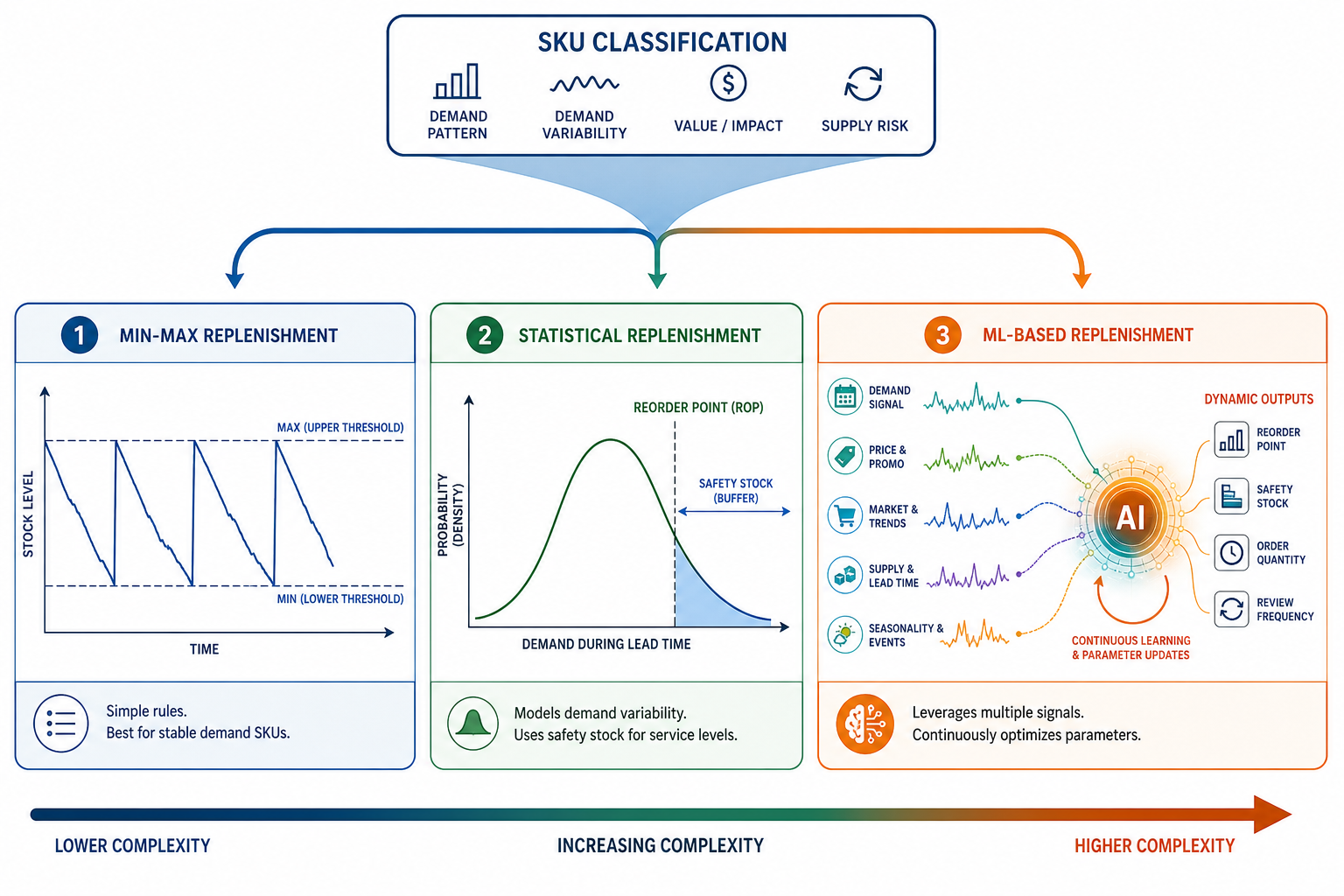
A min-max policy fires a replenishment order when on-hand inventory falls to a defined minimum level and orders enough to restore stock to a defined maximum level. The mechanics are simple: two thresholds, one trigger, one order quantity. The policy makes no assumptions about why demand is occurring, how variable it is, or how long the next replenishment cycle will take.
The governing assumption of min-max is that demand is stable and predictable enough that static thresholds will remain appropriate over time. It works adequately when product ranges are small, demand is consistent, and lead times are stable. It breaks when any of those conditions are violated—which is increasingly common in complex, multi-SKU environments.
Statistical Reorder-Point Policies: Linking Buffers to Service Level
Statistical reorder-point policies replace static thresholds with calculated parameters. The reorder point is derived from average demand during lead time plus a safety stock buffer. The safety stock buffer is sized to achieve a target service level given the observed variance in both demand and lead time.
The governing assumption here is that demand and lead time distributions are sufficiently stable and normal that variance can be estimated from historical data and used to set reliable buffers. This is a meaningful upgrade over min-max: the policy explicitly models uncertainty and connects buffer levels to a service-level commitment. For seasonal SKUs already assigned to a statistical policy tier, AI can dynamically recalibrate safety stock parameters as demand patterns shift within the season.
ML-Based Policies: Continuous Parameter Optimization
ML-based replenishment policies replace periodic parameter reviews with continuous optimization. Instead of setting a reorder point and safety stock from historical averages, the system ingests transactional history, demand signals, promotional calendars, and supply variability data to update parameters dynamically at the SKU-location level.
The governing assumption is that demand patterns are complex enough—and the SKU portfolio large enough—that no human-managed parameter review process can keep pace. ML-based policies are suited to high-SKU environments with volatile demand, promotional complexity, or omnichannel fulfillment requirements. They require substantially more data and organizational infrastructure than either of the simpler policy types.
| Policy Type | Trigger Mechanism | Uncertainty Model | Parameter Review | Governing Assumption |
|---|---|---|---|---|
| Min-Max | Stock hits floor threshold | None | Manual, infrequent | Demand is stable; static thresholds remain valid over time |
| Statistical Reorder-Point | Calculated reorder point based on demand and lead time variance | Demand and lead time variance modeled via safety stock formula | Periodic recalculation | Demand and lead time distributions are stable and approximately normal |
| ML-Based | Dynamic signal from continuously updated model | Probabilistic, incorporating multiple demand signals and supply variability | Continuous, automated | Demand patterns are too complex or volatile for static or periodically reviewed parameters |
Where Each Policy Breaks Down: Structural Failure Modes Under Real Conditions
Each policy type has conditions under which it produces systematically poor outcomes. Understanding these failure modes is more useful than understanding the policies' mechanics in isolation—because the failure modes are what tell you when a policy is mismatched to its SKU environment.
Min-Max Failure Modes
- Demand coefficient of variation (CV) above approximately 0.5: When demand variability is high relative to average demand, static thresholds cannot be set to simultaneously avoid stockouts and excess inventory. The policy will systematically over-stock during low-demand periods and under-stock during demand spikes.
- Volatile lead times: Min-max does not model lead time uncertainty. When supplier lead times fluctuate, the minimum threshold that was adequate for a 10-day lead time will produce stockouts when lead time extends to 18 days.
- SKU proliferation: As SKU count grows, manually maintained min-max parameters become increasingly stale. Parameters set during initial configuration are rarely revisited at the frequency required to track demand pattern changes across a large portfolio.
- Seasonal or promotional demand: Min-max cannot anticipate demand uplift. A threshold calibrated to baseline demand will trigger late replenishment during a promotion and leave excess stock after it ends.
Statistical Policy Failure Modes
- Intermittent demand: Safety stock formulas assume a reasonably continuous demand distribution. For SKUs with many zero-demand periods interspersed with sporadic orders, the variance estimate is unreliable and the resulting buffer will be either excessive or inadequate.
- Non-normal lead time distributions: Statistical safety stock formulas typically assume normally distributed lead times. When lead times have heavy tails—common with single-source suppliers or ocean freight—the formula underestimates required buffer at the service levels that matter most.
- Biased upstream forecast: Statistical reorder-point policies inherit whatever bias exists in the demand forecast they consume. A forecast that systematically underestimates demand during growth phases will produce reorder points that are consistently too low, regardless of how well the safety stock formula is constructed.
- Infrequent parameter recalculation: If safety stock and reorder point parameters are recalculated quarterly or annually, the policy behaves like a slower min-max for most of the year, losing the advantage of variance-based buffering during periods when demand patterns shift.
ML-Based Policy Failure Modes
- Insufficient history per SKU-location: ML models require enough transactional history to identify reliable demand patterns. New SKUs, recently introduced product lines, or SKU-location combinations with sparse sales data will produce unreliable model outputs.
- Absent model governance: Without monitoring for model drift, parameter lock mechanisms for critical SKUs, and override tracking, ML-generated replenishment signals can propagate errors at scale. A model that has drifted from current demand conditions will generate systematically wrong parameters across every SKU it manages.
- Organizational rejection: If planners do not understand how the model generates its recommendations, they will override it when outputs differ from their intuition—particularly during unusual demand periods when the model's recommendations are most likely to be correct. Unexplained model outputs erode trust faster than poor outcomes do.
- Data quality gaps: ML models amplify whatever patterns exist in the training data. Missing transactions, incorrectly recorded returns, or inconsistent location coding will produce models that have learned from corrupted signals.
The Selection Framework: Four Dimensions for Policy Assignment
Assigning a replenishment policy type to a SKU cluster is a structured decision with four evaluable dimensions. These dimensions are not equally weighted for every organization, but all four must be assessed before a policy assignment is made. Skipping any dimension produces a mismatch between policy capability and operating conditions.
Dimension 1: Demand Volatility
Demand volatility is the primary selection criterion. Measure it through three lenses: coefficient of variation (CV) for continuous demand SKUs, intermittency ratio for SKUs with frequent zero-demand periods, and promotional lift magnitude for SKUs subject to planned demand events.
As a practical threshold: SKUs with CV below approximately 0.3 and no promotional exposure are candidates for min-max. SKUs with CV between 0.3 and 0.7 with manageable intermittency are candidates for statistical policies. SKUs with CV above 0.7, significant intermittency, or material promotional complexity are candidates for ML-based policies—provided the other three dimensions are also met.
Dimension 2: Data History Depth
Policy type capability is constrained by available data. Statistical policies require enough demand history to estimate variance reliably—typically at least 12 months of clean transactional data per SKU-location to capture seasonal effects. ML-based policies require substantially more: a widely-cited practitioner threshold is 18 to 24 months of clean item-location demand history, along with reliable lead time records, promotion calendars, and supply reliability data.
Data history depth is often the binding constraint that prevents organizations from routing high-volatility SKUs to ML-based policies. New product introductions, recently added locations, and SKUs with significant data quality issues may need to be held at a statistical or even min-max tier until history accumulates and data quality issues are resolved.
Dimension 3: SKU Volume and Portfolio Complexity
Portfolio complexity determines whether the operational overhead of more sophisticated policies is justified. An organization managing 500 SKUs across two locations can maintain statistical policies manually with reasonable effort. An organization managing 50,000 SKU-location combinations cannot—the parameter review burden alone makes statistical policies operationally unsustainable without automation, and ML-based policies become necessary to manage the portfolio at scale.
Portfolio complexity also interacts with network structure. Organizations with multi-echelon distribution networks face policy coordination requirements that elevate the minimum viable policy sophistication—see AI multi-echelon inventory optimization by industry vertical for network-level policy coordination considerations.
Dimension 4: Organizational Readiness
Organizational readiness covers three sub-factors: planner capability to interpret and act on model-generated recommendations; model governance infrastructure including override tracking, parameter lock mechanisms, and drift monitoring; and ERP or WMS integration capability to receive and execute policy-generated orders without manual re-entry.
An organization without model governance infrastructure should not deploy ML-based policies at scale, regardless of how well its demand data supports them. The governance layer is not optional overhead—it is what prevents ML-generated errors from propagating across the entire managed SKU portfolio before anyone notices.
SKU Segmentation and Policy Mapping: A Decision Matrix
The four framework dimensions combine into a practical decision matrix. The primary axes for initial policy assignment are demand volatility and data history depth. SKU volume and organizational readiness function as qualifying conditions that may constrain or elevate the policy tier a cluster can realistically be assigned to.
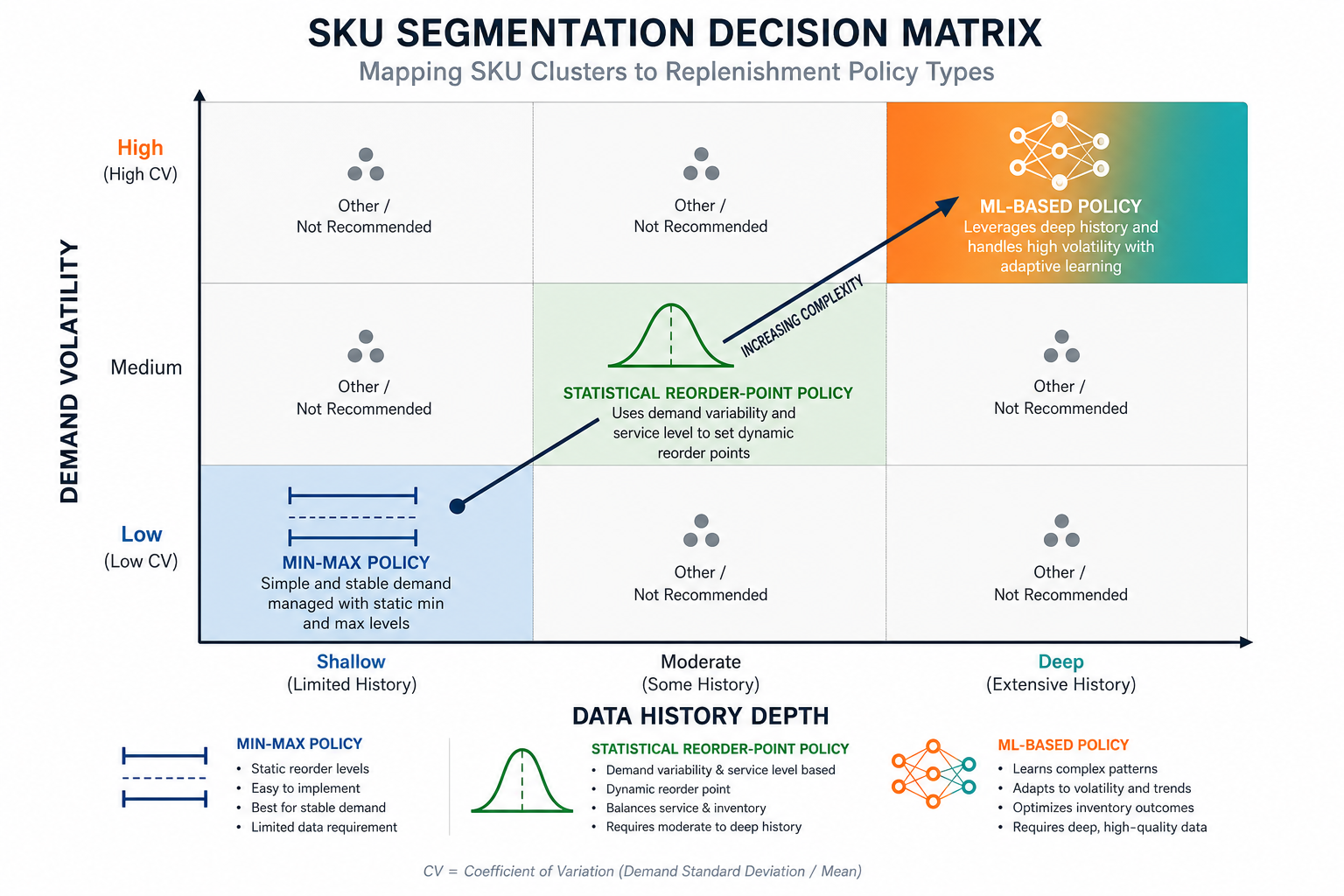
| SKU Cluster Profile | Demand Volatility (CV) | Data History | Typical Policy Tier | Illustrative Examples |
|---|---|---|---|---|
| Stable, high-volume, predictable | < 0.3, no intermittency | Any | Min-Max | Core consumables, standard packaging materials, high-velocity commodity items |
| Moderate volatility, seasonal variation | 0.3–0.7, limited intermittency | 12+ months clean history | Statistical Reorder-Point | Seasonal apparel basics, mid-tier MRO parts, regional distribution SKUs |
| High volatility, promotional complexity | > 0.7 or significant intermittency | 18–24+ months clean history | ML-Based | Fashion items, promotional CPG SKUs, omnichannel fulfillment items |
| New SKU or sparse history | Any | < 12 months or data quality issues | Min-Max (temporary) | New product introductions, recently added locations, post-merger SKU integrations |
The new-SKU row deserves explicit attention. Organizations frequently attempt to apply ML-based policies to new product introductions because those SKUs are often the most volatile and commercially important. This is backward: new SKUs lack the history ML models require, and the cost of a bad ML-generated parameter on a high-visibility new product is substantial. New SKUs should start at min-max, graduate to statistical once 12 months of clean history is available, and route to ML-based tiers only when data prerequisites are met.
For short-lifecycle SKUs—fashion, seasonal, or trend-driven items—the upstream forecasting method matters as much as the replenishment policy tier. These SKUs typically route to ML-based policies when history is available, but require probabilistic demand forecasting as the input. For the forecasting method appropriate to these SKUs, see probabilistic demand forecasting for short-lifecycle SKU retail.
The AI Role: Automating Policy Assignment and Dynamic Reclassification
AI frameworks change the policy selection decision itself—not just the parameters within a chosen policy. This is the distinction that matters most for organizations evaluating AI-driven inventory tools.
In a manual process, policy assignment happens once during implementation and is revisited infrequently. SKUs that have migrated from stable to volatile demand patterns remain in the wrong policy tier until a planner notices the symptoms—stockouts, excess inventory, or expediting costs—and investigates. By the time the mismatch is identified, inventory performance has already degraded.
AI-enabled policy frameworks do two things that manual processes cannot: they classify SKUs into policy-appropriate clusters continuously, and they trigger reclassification when demand pattern changes shift a SKU across a tier boundary. The classification engine monitors CV, intermittency, and history depth at the SKU-location level and flags clusters whose characteristics no longer match their assigned policy tier.
Early Replenishment Signals and Dynamic Differentiation
ML-based systems can also generate early replenishment signals that distinguish between SKUs gaining demand momentum and those losing it—what some platforms describe as identifying runner and laggard products. This differentiation is not available from static policies: a min-max rule treats a SKU with accelerating demand the same as one with flat demand until the reorder threshold is hit. An ML system that has detected the acceleration can signal replenishment earlier, reducing the risk of a stockout during the demand ramp.
- Continuous SKU classification: AI monitors demand pattern metrics at the SKU-location level and maintains policy tier assignments without requiring manual planner review of every item.
- Dynamic reclassification triggers: When a SKU's CV, intermittency ratio, or data history crosses a tier boundary threshold, the system flags it for reclassification rather than waiting for a periodic review cycle.
- Early demand signal detection: ML models identify demand acceleration or deceleration earlier than static thresholds, enabling proactive replenishment adjustments before inventory positions become problematic.
- Parameter generation at scale: For large SKU portfolios, AI removes the operational impossibility of manually maintaining statistically appropriate parameters for every SKU-location combination.
Governance for Hybrid Policy Environments
Most organizations that implement a structured policy selection framework will end up running multiple policy types simultaneously across their SKU portfolio. This is operationally valid and expected—the goal is not to standardize on a single policy type, but to match policy type to SKU cluster characteristics. The governance challenge is what breaks when multiple policies operate without explicit coordination.
What Breaks Without Governance
- Conflicting ordering signals: When a SKU is managed by a statistical policy at the regional DC and a min-max policy at the store level, the two systems can generate orders that work against each other—the store depletes safety stock that the DC was holding as a buffer, triggering a DC replenishment order that arrives after the stockout has already occurred.
- Unauthorized parameter overrides: Planners who distrust ML-generated parameters will override them, particularly during unusual demand periods. Without override tracking, these interventions are invisible to model governance and accumulate as undetected policy drift.
- Critical SKU exposure: High-margin or supply-constrained SKUs managed by ML-based policies need parameter lock mechanisms that prevent automated reclassification from changing their replenishment parameters without human review. Without locks, a demand pattern anomaly can trigger a parameter change that creates a stockout on a SKU where a stockout is commercially unacceptable.
- Policy change without approval: In a hybrid environment, moving a SKU from one policy tier to another is a material operational change. Without an approval workflow, tier changes can be made by automated classification systems or individual planners without visibility to downstream stakeholders.
The governance requirements for hybrid policy environments are not complex, but they must be explicitly designed. They do not emerge naturally from ERP configuration or AI platform deployment.
- Policy change approval workflow: Tier changes for SKUs above a defined criticality or volume threshold require explicit approval, not just automated reclassification.
- Parameter lock mechanisms: Critical SKUs have parameters that can only be changed through a supervised review process, not by automated model updates.
- Override tracking: Every planner override of a model-generated parameter is logged with timestamp, planner ID, and reason code. Override rates are reviewed as a model health indicator.
- Cross-echelon policy coordination: In multi-echelon networks, policy assignments at different network nodes must be coordinated to prevent the inventory positioning conflicts described above.
Migration Sequencing: From Min-Max Defaults to Statistical to ML-Based
The correct migration sequence is: policy selection framework first, then data readiness assessment, then vendor evaluation. Most organizations reverse this order—they evaluate vendors, select a platform, and then discover that their data and policy architecture cannot support the platform's capabilities. The reversal is expensive and common.
Vendor evaluation before policy architecture definition means you are evaluating platforms against requirements you haven't specified. A vendor demo that shows ML-based replenishment working smoothly tells you nothing about whether your SKU portfolio, data quality, and organizational readiness support that capability. The policy selection framework defines what you need; vendor evaluation determines which platform can deliver it.
Moving SKU Clusters from Min-Max to Statistical
- Identify candidate clusters: Apply the demand volatility dimension from the selection framework to identify SKUs where CV or seasonal variation exceeds the min-max threshold but does not yet warrant ML-based treatment.
- Audit data quality: Verify that 12+ months of clean transactional history exists at the SKU-location level. Resolve data quality issues—missing transactions, duplicate records, incorrectly coded returns—before calculating statistical parameters.
- Set service-level targets by segment: Statistical policies require explicit service-level targets as inputs. These should be differentiated by SKU criticality, margin, and customer impact—not applied uniformly across the portfolio.
- Calculate and validate initial parameters: Generate initial reorder points and safety stock levels from the statistical formula, then validate against recent demand history before activating. Identify outliers where the formula produces implausible results and investigate the cause.
- Establish parameter review cadence: Statistical policies require periodic recalculation to remain accurate. Define the review frequency—at minimum quarterly, monthly for high-velocity or volatile SKUs—and assign ownership.
Moving SKU Clusters from Statistical to ML-Based
- Confirm data prerequisites: Verify 18–24 months of clean item-location demand history, lead time distribution data, promotion calendars, and supply reliability records. These are not negotiable minimums—ML model quality degrades significantly below these thresholds.
- Build model governance infrastructure before deployment: Override tracking, parameter lock mechanisms, and model drift monitoring must be in place before ML-generated parameters go live. Retrofitting governance after deployment is substantially harder than building it in advance.
- Run parallel operation: Operate the ML-based policy in shadow mode alongside the existing statistical policy for a defined period—typically 4 to 8 weeks. Compare ML-generated parameters against statistical parameters and investigate significant divergences before switching.
- Address planner trust explicitly: Planners who will manage ML-generated parameters need to understand the model's logic at a level sufficient to evaluate its recommendations, not just execute them. This is a change management task, not a training task—it requires deliberate investment in building planner confidence in model outputs.
- Define reclassification triggers: Establish the criteria under which SKUs will be moved back to statistical tiers—for example, if data quality degrades, if the SKU is discontinued, or if the model's override rate exceeds a defined threshold.
Data Prerequisites by Policy Tier
The table below summarizes minimum data requirements for each policy tier. These are readiness thresholds, not optimization targets—meeting them is necessary but not sufficient for successful policy deployment. For a full audit of data readiness before policy tier selection, see the data readiness assessment implementation guide for AI inventory optimization.
| Data Element | Min-Max | Statistical Reorder-Point | ML-Based |
|---|---|---|---|
| Transactional demand history | Any (used for initial threshold calibration only) | 12+ months, clean, per SKU-location | 18–24+ months, clean, per SKU-location |
| Lead time data | Average lead time per supplier | Lead time mean and variance per supplier or lane | Lead time distributions per supplier or lane, including tail behavior |
| Service-level targets | Not required | Required per SKU segment | Required per SKU segment; used as model training objective |
| Promotion calendars | Not required | Useful for seasonal adjustment | Required for SKUs with promotional exposure |
| Supply reliability records | Not required | Useful for lead time variance estimation | Required; used to model supply-side uncertainty |
| SKU-location master data quality | Basic accuracy required | Consistent coding required for variance estimation | High accuracy required; inconsistencies corrupt model training data |
Policy Selection as a Recurring Governance Decision
The organizational failure that produces min-max by default is not a one-time implementation error—it is the absence of a recurring process for reviewing whether the current policy architecture remains appropriate. Demand patterns shift. SKU portfolios grow and contract. Supplier reliability changes. New distribution channels introduce new fulfillment complexity. Each of these changes can invalidate a policy assignment that was correct when it was made.
Policy selection should be built into the planning cycle as a structured review, not treated as a configuration decision made once during system implementation. At minimum, this means reviewing SKU cluster assignments quarterly, triggering reclassification reviews when demand pattern metrics cross tier thresholds, and including policy architecture in the scope of any significant demand environment change—new product launches, channel expansions, supplier consolidations.
AI-enabled classification systems make recurring policy review operationally feasible at scale. Without automation, reviewing policy tier appropriateness for 10,000 SKU-location combinations quarterly is not a realistic planning task. With automated monitoring of the four selection dimensions, the review becomes an exception management process: the system flags clusters that have crossed tier boundaries, and planners review and approve reclassification recommendations rather than generating them from scratch.
The framework in this guide covers the policy selection layer—which architecture to deploy for which SKU segment. The downstream optimization questions—how to calibrate safety stock within a statistical policy, how to configure ML models for specific demand pattern types, how to coordinate policy across a multi-echelon network—are addressed in the adjacent articles this guide links to throughout. The policy selection decision is the prerequisite for all of them.
Comments
Join the discussion with an anonymous comment.